Fecha de recepción: 28 de septiembre de 2017
Fecha de aceptación: 13 de octubre de 2017
RESUMEN
La presente investigación evalúa la eficacia de los modelos multivariados dinámicos optimizados con fuerza bruta computacional para la acción Rio Tinto Limited, tomando como variable exógena el índice bursátil DOW JONES. Se aplica modelo multivariado dinámico optimizado con fuerza bruta para predecir el comportamiento de sus cotizaciones a la semana siguiente de la última fecha analizada. El objetivo de este análisis es construir un modelo predictivo con un porcentaje de predicción de signo por encima del 60% y, por consiguiente, mejorar la toma de decisiones para los inversionistas en opciones binarias. Esta es una investigación de carácter exploratorio y descriptivo. Se utilizó la información bibliográfica disponible física y digitalmente (internet) para conocer la cotización de ambos índices comprendidos en el periodo 30 de septiembre de 2013-02 de octubre de 2017, pudiéndose observar la variación de una semana a otra y comparar los datos reales con las variaciones pronosticadas. La acción Rio Tinto Limited, elegida para este estudio, tranza en bolsa y sus cotizaciones históricas e información financiera se pueden obtener en Yahoo Finanzas. Se pudo concluir que es factible construir un modelo predictivo con una capacidad de predicción superior al 60% para la acción Rio Tinto Limited. Los modelos se construyeron con 1.000.000 de iteraciones con fuerza bruta, dado que la optimización por simplex o solver no alcanzó el resultado esperado. Se usaron 12 variables que influyen en el modelo para el periodo analizado. Se entiende como alcanzado el objetivo. Este estudio-modelo puede ser útil para tomadores de decisiones o inversionistas de este sector.
ABSTRACT
The present research evaluates the efficiency of dynamic multivariate models optimized with computational gross force for the Rio Tinto Limited stock, taking as an exogenous variable the DOW JONES stock index. We apply a dynamic multivariate model optimized with brute force to predict the behavior of its quotes the week after the last analyzed date. The objective of this analysis is to construct a predictive model with a sign prediction percentage above 60% and therefore improve the decision making for the investors in binary options. This is an exploratory as well as descriptive research. The information available in bibliography and the internet was used to know the quotation of both indexes included in the period September 30, 2013 to October 2, 2017, being able to observe the variation from one week to another, and thus to compare the real data with the predicted variations. The Rio Tinto Limited stock, chosen for this study, trades on the stock exchange and its historical quotes and financial information can be obtained from Yahoo Finance. It was possible to conclude that if it is feasible to construct a predictive model with a prediction capacity greater than 60% for the Rio Tinto Limited share. The models were constructed with 1,000,000 iterations with brute force, since the simplex or Solver optimization did not reach the expected result. We used 12 variables that influence the model for the period analyzed. The objective is understood as achieved, and this study and model can be useful for decision makers or investors in this sector.
1. INTRODUCCIÓN
En el mundo financiero existe un fenómeno que ha concentrado el interés de muchos actores, tales como analistas, inversionistas individuales e institucionales, académicos, aficionados: se trata de la predicción del comportamiento del mercado financiero para decisiones de inversión en sus distintos instrumentos (acciones, índices bursátiles, derivados, entre otros). Es tanto el interés por predecir el comportamiento del mercado financiero que hasta el día de hoy se han adoptado distintos modelos y/o procedimientos que buscan predecir, con cierto margen de probabilidad, los comportamientos del mercado, representando una solución para este fenómeno de situaciones futuras e inciertas.
La hipótesis de mercados eficientes (Fama, 1970) plantea que el mercado refleja completa y correctamente toda la información pertinente para la determinación de los precios de los activos. Debido a que el surgimiento de nueva información es de carácter aleatorio, los cambios de los precios accionarios también lo serían. Esto ha llevado a muchos analistas financieros y académicos a señalar que las fluctuaciones de los precios accionarios siguen en una caminata aleatoria (random walk), donde el concepto de aleatoriedad se refiere a que las variaciones de precios son generadas a partir de un cierto proceso estocástico. No obstante, varios estudios han concluido que existe evidencia significativa de que los precios accionarios no siguen una caminata aleatoria y muestran que los rendimientos accionarios son predecibles en algún grado (véase, por ejemplo, Lo y MacKinley, 1988; Conrad y Kaul, 1988, 1989; DeBondt y Thaler, 1985; Fama y French, 1988; Easley y O´Hara, 1994).
Tal como se señaló anteriormente, los comportamientos en el mercado son predecibles en alrededor de un 60% y 70% en la variación de signo (Fama y French, 1992) y según lo evidenciado en trabajos posteriores para algunos mercados (Parisi, Parisi y Díaz, 2006).
Dado este concentrado interés por parte de diversos actores, es que esta investigación es una continuación y actualización de las investigaciones propuestas por Parisi, Parisi y Cornejo (2004) en la creación de modelos multivariados dinámicos con base en algoritmos genéticos recursivos, agregando variables exógenas y optimizado con un método de fuerza bruta operacional (Parisi, 2016), lo que permitirá construir infinitos escenarios aleatorios para así encontrar un coeficiente que maximice el porcentaje de predicción de signo, después de alcanzar la máxima capacidad de trabajo de un ordenador ocupando como desarrollador del modelo el software Excel. Este estudio se centra en el comportamiento de la empresa cuprífera Rio Tinto Limited y su acción RIO.AX en el mercado de valores New York Stock Exchange (NYSE).
El concepto de técnica de fuerza bruta en mercados financieros fue utilizado como método predictor (Parisi, 2016) y es una continuación y desarrollo lógico de investigaciones anteriores basadas en autores como Arango, Velásquez y Franco (2013), quienes utilizan técnicas de lógica difusa para predecir índices accionarios; y Atsalakis (2016), quien innova en un modelo que busca predecir los precios del carbono usando inteligencia computacional. Asimismo, encontramos a Pierdzioch (2015), quien utiliza métodos artificiales para la predicción en las fluctuación del precio del oro, de manera muy parecida a los investigadores Shafiee y Topal (2010), quienes anteriormente tratan de prever el precio del oro. Según Parisi (2016), las técnicas antes mencionadas cada vez han ido mejorando en su capacidad predictiva gracias a los avances computacionales en velocidad y tratamiento de datos, lo cual no justifica buscar los llamados atajos y se hace atingente la no utilización de algoritmos en primera diferencia, siendo mejor usar directamente fuerza bruta en primera diferencia, es decir las variables alcanzarían valores ceros si es que el coeficiente generado a través de números aleatorios llega a valor del coeficiente cero.
En consecuencia, este estudio, como una primera parte, explica brevemente los modelos actuales según distintos autores contemporáneos que buscan la mejor predicción de variaciones de signo. Luego, se establecen los contenidos metodológicos en el uso de este estudio para la empresa cuprífera Rio Tinto Limited para presentar resultados y conclusiones finales.
2. REVISIÓN DE LITERATURA
El estudio se ha acotado a caracterizar los modelos de predicción de precios con base en la inteligencia artificial, la cual tiene adeptos y detractores, estando en constante revisión y desarrollo.
2.1 Algoritmos genéticos
Los algoritmos genéticos consisten en una función matemática o una rutina que simula el proceso evolutivo de las especies, teniendo como objetivo encontrar soluciones a problemas específicos de maximización o minimización (Holland, 1975). Así, el algoritmo genético recibe como entrada una generación de posibles soluciones para un problema y arroja como salida los especímenes más aptos (es decir, las mejores soluciones) para que se apareen y generen descendientes, los que deberían tener mejores características que las generaciones anteriores.
Los algoritmos genéticos trabajan con códigos que representan a cada una de las posibles soluciones al problema. Por ello, es necesario establecer una codificación para todo el rango de soluciones antes de comenzar a utilizar el algoritmo. Al respecto, Davis (1994) señala que la codificación más utilizada es la representación de las soluciones por medio de cadenas binarias (conjuntos de ceros y unos).
Según Bauer (1994), este método puede ser utilizado fácilmente en aplicaciones financieras. Davis (1994) muestra una aplicación de algoritmos genéticos en la calificación de créditos bancarios que resultan mejor que otros métodos, como las redes neuronales, debido a la transparencia de los resultados obtenidos. Kingdon y Feldman (1995) usaron algoritmos genéticos para hallar reglas que pronosticaran la bancarrota de las empresas, estableciendo relaciones entre las distintas razones financieras. Bauer (1994) utilizó algoritmos genéticos para desarrollar técnicas de transacción que indicaran la asignación mensual de montos de inversión en dólares y marcos; Pereira (1996) los utilizó para encontrar los valores óptimos de los parámetros usados por tres reglas de transacción distintas para el tipo de cambio dólar estadunidense/dólar australiano: los parámetros obtenidos mostraron resultados intramuestrales positivos, los cuales disminuyeron al aplicar las reglas fuera de la muestra, aun cuando continuaron siendo rentables.
En tanto, Allen y Karjalainen (1999) usaron algoritmos genéticos para aprender reglas de transacción para el índice S&P 500 y emplearlas como un criterio de análisis técnico y, una vez cubiertos los costos de transacción, encontraron que el exceso de rendimiento calculado sobre una estrategia buy and hold, durante el periodo de prueba extramuestral, no era congruente. Kim y Han (2000) mostraron que los algoritmos genéticos pueden ser usados para reducir la complejidad y eliminar factores irrelevantes, lo que resultó mejor que los métodos tradicionales para predecir un índice de precios accionario. Por otra parte, Feldman y Treleaven (1994) señalaron que la mayor desventaja de los algoritmos genéticos es la dificultad que presentan para escoger una técnica de codificación manejable, así como para determinar el tipo de selección y las probabilidades de los operadores genéticos, ya que no hay reglas fijas en esta materia.
2.2 Modelos ARIMA
ARIMA (Auto Regresive Integrated Moving Average) es un modelo econométrico propuesto por los investigadores Box y Jenkins en los 70 para predecir series de tiempo. Popularmente es conocida como metodología Box-Jenkins, aunque también es conocida como metodología o modelos ARIMA. Consta de tres componentes:
- Proceso Autorregresivo (AR): se define como modelo autorregresivo si la variable endógena de un periodo t es explicada por sí misma en las observaciones o datos pasados, multiplicados por un coeficiente que le da un peso específico a la información pasada.
- Proceso Integrado (I): se refiere al estado de la variable, es decir si se va a trabajar sobre el valor sin modificación sobre su primera o segunda diferencia, entendiéndose la primera diferencia simplemente como la primera variación de la serie en estudio. Por ejemplo, una serie de precios se entiende como integración en cero. Es decir, se trabajará con la variable pura, lo que en términos generales no es recomendable, dado que tienen tendencia y no se pueden modelar en esas condiciones. Un grado de integración 2 indica que el modelo se construirá sobre la variación de la serie en estudio, es decir no se modela el precio, sino la variación del precio. Se obtiene un modelo para la variación de precios, se le suma el precio anterior y se obtiene la proyección de precios, es decir en niveles ARIMA y cero.
- Proceso de Media Móvil (MA): es aquel que explica el valor de una determinada variable en un periodo t en función de un término independiente y una sucesión de errores correspondientes a periodos precedentes, ponderados convenientemente. A continuación, se muestra la simbología y componentes de un modelo ARIMA:
ARIMA (p, d, q)
P = AR () autorregresivo como variable explicativa.
D= Integrado
Q= Error como variable explicativa (media móvil de los errores).
2.3 Autómatas celulares
Los autómatas celulares son mecanismos artificiales que tratan de imitar las propiedades o sistemas similares a los de los seres vivos a través de la interacción entre individuos simples de dichos sistemas. Se basa en un panel con un conjunto finito de células o autómatas simples, donde cada uno puede adoptar un estado posible de un conjunto finito de estados, determinado por su estado anterior y el estado de las células vecinas.
Malamud y Turcotte (2000) (citado por Cepeda A. y Gonzáles G., 2009) proponen que “los estados de las células van evolucionando en tiempo discreto, de acuerdo con una regla local o un conjunto de reglas, las cuales pueden ser basadas en el estado anterior de la célula, o en el de sus vecinos. En cada período, la regla se le aplica al conjunto de células, entregando una nueva generación de autómatas”.
Cada autómata simple genera una salida a partir de varias entradas, modificando su estado de acuerdo con una función de transición a través de generaciones. Por lo tanto, en un autómata celular el estado de una célula en una generación determinada depende únicamente de su propio estado y el de las células vecinas de la generación anterior.
Estos son usados para modelar sistemas complejos de cualquier índole, por lo que no sorprende que en las finanzas y la economía los expertos hayan hecho lo mismo. Varios especialistas han hecho investigaciones y han utilizado a los autómatas celulares para predecir los cambios en los signos de los precios de las acciones y los resultados han sido positivos.
2.4 Redes neuronales
De acuerdo con Martín del Brío y Sanz (1997), las redes neuronales artificiales «son sistemas de procesamiento que copian esquemáticamente la estructura neuronal del cerebro para tratar de reproducir sus capacidades» (pág. 387). En consecuencia, son una clase de modelo no lineal flexible que se caracteriza que contempla sistemas paralelos, distribuidos y adaptativos, todo lo cual se traduce en un mejor rendimiento y en una mayor velocidad de procesamiento. Las redes neuronales pueden entenderse como modelos multiecuacionales o multietapas, en que el output de unas constituye el input de otras. En el caso de las redes multicapas, existen etapas en las cuales las ecuaciones operan en forma paralela. Los modelos de redes neuronales, al igual que, por ejemplo, los modelos de suavizamiento exponencial y de análisis de regresión, utilizan inputs para generar un output en la forma de una proyección. La diferencia radica en que las redes neuronales incorporan inteligencia artificial en el proceso que conecta los inputs con los outputs (Kuo y Reitsch, winter 1995-1996).
Herbrich, Keilbach, Graepel, Bollmann-Sdorra y Obermayer (2000) señalan que la característica más importante de las redes neuronales es su capacidad para aprender dependencias basadas en un número finito de observaciones, donde el término “aprendizaje” significa que el conocimiento adquirido a partir de la muestra de observaciones históricas puede ser empleado para proporcionar una respuesta correcta ante datos no utilizados en el entrenamiento de la red y, por lo tanto, no conocidos por esta. La literatura sugiere que las redes neuronales poseen varias ventajas potenciales sobre los métodos estadísticos tradicionales, destacándose que pueden ser aproximadoras de funciones universales, aun para funciones no lineales (Homik, Stinchcombe y White, 1989), lo que significa que ellas pueden aproximar automáticamente cualquier forma funcional (lineal o no lineal) que mejor caracterice los datos, permitiéndole a la red extraer más señales a partir de formas funcionales subyacentes complejas (Hill, Marquez, O’Connor y Remus, 1994). Cabe señalar que algunos investigadores han encontrado que, en general, los mercados financieros se comportan de una forma no lineal, cuestión que ha favorecido el empleo de modelos de redes neuronales, ya que, como se dijo anteriormente, estas han evidenciado un buen desempeño en modelamientos no lineales.
Es posible distinguir al menos dos importantes aplicaciones de las redes neuronales en las áreas de economía y finanzas: primero, la clasificación de agentes económicos, por ejemplo, para obtener una estimación de la probabilidad de quiebra (Wilson y Sharda, 1994); segundo, la predicción de series de tiempo (Tang et al., 1991). Cabe destacar que el propósito de un modelo de predicción es capturar patrones de comportamiento en datos multivariados que distingan varios resultados, cosa que es bien realizada por los modelos no paramétricos de redes neuronales, los cuales han sido desarrollados para predecir valores de índices bursátiles y de activos individuales, situándose la mayoría de las primeras investigaciones y aplicaciones en mercados establecidos en U.S.A., Gran Bretaña y Japón. Dichos modelos han sido empleados para predecir el nivel o signo de los retornos de índices bursátiles, entre otras aplicaciones relacionadas a la toma de decisiones en las áreas de finanzas e inversión.
2.5 La técnica de la “Fuerza Bruta”
La técnica fuerza bruta, según Parisi (2016), utiliza la capacidad de las computadoras para poder encontrar la mejor solución a un problema de optimización. Esta técnica aplicada a los modelos multivariados dinámicos simula la inteligencia humana, puesto que genera escenarios diferentes en los cuales cada uno de ellos brinda una solución única al problema. La función de este modelo multivariado dinámico con fuerza bruta es comparar los nuevos escenarios generados con los anteriores y elegir el mejor. Dicho de otra manera, recuerda, al igual que un humano, el propio comportamiento para ofrecer una mejor solución a determinado problema; si ese comportamiento solucionó el problema, cada vez que suceda un escenario parecido se utilizará el mismo comportamiento. De la misma manera, los modelos multivariados dinámicos con fuerza bruta utilizan el mejor modelo.
En los modelos multivariados dinámicos, que son modelos de regresión, la técnica fuerza bruta permite generar infinitos coeficientes de un universo establecido, para darle un peso a cada variable establecida y evaluada en el modelo. Incluso se puede afirmar que usando fuerza bruta se puede contemplar todos los escenarios del universo establecido, siendo así, una mejora a los algoritmos genéticos, los cuales sólo buscan alrededor de un punto en el universo que ofrece una solución de primera instancia óptima.
Como afirma Durán (2006), la fuerza bruta consiste en enlistar todos los casos y para cada uno calcular la solución, identificando de este modo el caso que ofrezca la mejor solución. Asimismo, Riveros (2015), en un estudio para encontrar la solución óptima al problema del camino más corto para una empresa de logística, comenta que la solución más directa es con fuerza bruta, es decir evaluar todas las posibles combinaciones (de recorridos) y quedarse con el trayecto que utiliza una menor distancia.
Los métodos mencionados anteriormente sirven para resolver los mismos problemas de optimización simulando la inteligencia humana. Muchos científicos y expertos en ciencias sociales a lo largo de los años han estado trabajando en el desarrollo de cada vez mejores métodos para la solución de problemas. Lo curioso es que el primer método empleado para resolver problemas es el conocido como fuerza bruta. Desde tiempos antiguos el hombre utiliza la fuerza bruta para resolver los problemas. Pero ¿por qué se crearon nuevos métodos si con este bastaba? Sencillo: los problemas cada vez alcanzaron dimensiones mayores y más complejas, lo cual hizo necesario crear métodos que demoraran menos en resolver un problema.
Como se ha dicho, la fuerza bruta prueba una a una las diferentes condiciones y características de un sistema para resolver el problema. Una vez que se encuentra la solución, se queda con dicho sistema. Se dejó de usar fuerza bruta puesto que no existía la capacidad para resolver problemas que requerían la evaluación de una cantidad de variables considerada demasiado grande. Sin embargo, hoy en día la tecnología ha vuelto a superar los problemas, y cualquier persona puede contar con un computador con recursos altamente efectivos capaces de procesar información mucho más rápido que aquellas computadoras de hace 10 años atrás. Por lo tanto, ahora es prudente e incluso más eficaz volver a utilizar la técnica fuerza bruta utilizando la capacidad de una computadora de alta tecnología.
3. METODOLOGÍA
3.1 Tipo de investigación y diseño
Se ha establecido como una investigación de carácter exploratoria que busca validar a partir de un modelo multivariado dinámico la incorporación de la técnica de fuerza bruta (Parisi, 2016) para obtener un porcentaje de predicción de signo significativo respecto a otros modelos en la acción RIO.AX. También es correlacional puesto que utiliza la relación entre el precio pasado como base de proyección del precio futuro de un valor, necesariamente determinando la relación en específico.
La población para este estudio contempla los precios de la acción Rio Tinto Limited que transan en el New York Stock Exchange (NYSE) a partir de una muestra de precios de cierre semanales, obtenido de la base de datos de precios históricos del portal web yahoo.com sección finanzas correspondiente al periodo 30 de septiembre de 2013-02 de octubre del 2017. Por la naturaleza de este estudio, se utilizó recopilación documental o datos secundarios, lo que implica la revisión de documentos, registros públicos y archivos físicos o electrónicos (Hernández, 2010), utilizando el nemotécnico de la acción: Rio Tinto Limited (RIO.AX) totalizando 209 observaciones.
Se usaron los valores de cierre semanales 1 debido a que los administradores de fondos de inversión tienden a recomponer sus carteras en función de pronósticos semanales.
3.2 Análisis estadístico de datos
Para efectos de evaluar el poder predictivo de frecuencias semanales, los modelos multivariados dinámicos utilizados son modelos de series de tiempo que expresan el comportamiento de una variable en función de sus valores rezagados, de variables exógenas rezagadas y de los rezagos de los residuos (errores) del modelo. La variable exógena incluida es el DJI2, considerado un indicador líder de lo que ocurre en los mercados bursátiles internacionales, sobre todo en una región integrada geográfica y comercialmente como América del Norte, resumiendo el comportamiento del mercado.
El modelo multivariado dinámico usado para predecir el signo de las fluctuaciones semanales de la acción evaluada se presenta en la ecuación 1.
Dow Jones Industrial es el índice que agrupa a las 30 empresas más grandes y representativas que transan en el mercado de EE.UU.
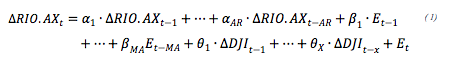
En los que corresponde al término de error del modelo; RIO.AX a las cotizaciones de la acción RIO.AX y DJI a las cotizaciones del índice Dow Jones, que son las variables de la ecuación. Los subíndices AR, MA y X representan el máximo orden de rezagos de las variables independientes. Los coeficientes α, β y θ son los coeficientes mejor adaptados que de acuerdo con su valor le dan un peso determinado, por el modelo, a las variables. Estos últimos indican que tanto afecta la variable incluida en el precio del valor en estudio.
- Evaluación de la predicción
En concordancia con el punto anterior, se evaluó la calidad de cada modelo en función del porcentaje de predicción de signo alcanzado (PPS). La evaluación se realizó sobre la base de un conjunto extramuestral de 209 datos semanales, por medio de un proceso recursivo correspondiente a la ventana de datos entre 30 de septiembre de 2013 y el 2 de octubre del 2017. Metodológicamente, la recursividad ha sido empleada para medir el desempeño de modelos de redes neuronales que buscan predecir periodos de recesión en los Estados Unidos (Qi, 2001; Estrella y N’lishkin, 1998) y para proyectar el signo de las variaciones de índices bursátiles Internacionales (Parisi, Parisi y Guerrero, 2003; Parisi, Parisi y Díaz, 2006).
Se utilizó la muestra total tanto para estimar los coeficientes α, β y θ de cada modelo por medio de la minimización de la suma del cuadrado de los residuos del modelo, como para evaluar la capacidad predictiva de los modelos. Para ello, se comparó el signo de la proyección con el signo de la variación observada en cada i-ésimo periodo, en el que i = 1, 2,…, m. Si los signos entre la proyección y el observado coinciden, entonces se puede señalar que aumenta la efectividad del modelo analizado y, en caso contrario, disminuye su capacidad predictiva.
Una vez proyectado el signo de la variación del precio para el periodo n+1, la variación observada correspondiente se incluye en la muestra de tamaño de n con objeto de reestimar los coeficientes del modelo, contando ahora con una observación más. Así, el mismo modelo, pero con sus coeficientes recalculados, es utilizado para realizar la proyección correspondiente al periodo n+2. Este procedimiento recursivo se efectuó una y otra vez hasta acabar con las observaciones del conjunto extramuestral. Finalmente, el PPS de cada modelo se calculó de la siguiente forma:
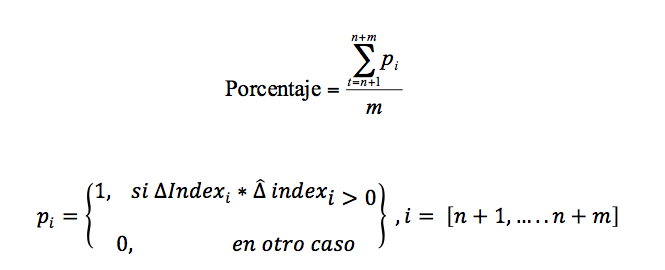
en la que ∆ representa la variación observada, ![]() la variación estimada,
la variación estimada, ![]() De esta manera, el modelo multivariado dinámico construido con la técnica fuerza bruta fue evaluado en función de su capacidad para predecir el signo de los movimientos de los precios de la acción RIO.AX. Además, en esta etapa se aplicó la prueba de acierto direccional de Pesaran y Timmermann (1992), con objeto de medir la significancia estadística de la capacidad predictiva de cada uno de los modelos analizados.
De esta manera, el modelo multivariado dinámico construido con la técnica fuerza bruta fue evaluado en función de su capacidad para predecir el signo de los movimientos de los precios de la acción RIO.AX. Además, en esta etapa se aplicó la prueba de acierto direccional de Pesaran y Timmermann (1992), con objeto de medir la significancia estadística de la capacidad predictiva de cada uno de los modelos analizados.
Luego, para analizar si la capacidad predictiva de los modelos se traduce en beneficios económicos, se calculó la rentabilidad acumulada que se habría obtenido si se hubiesen comprado o vendido los valores en estudio siguiendo las recomendaciones de compra-venta del modelo de predicción. Para ello, la proyección de una variación positiva de los precios (un alza del mercado) fue interpretada como una señal de compra, mientras que el pronóstico de una variación negativa (una caída del mercado) fue interpretado como una señal de venta. Se supuso una inversión inicial de 100 mil dólares y la rentabilidad acumulada se calculó sobre un conjunto extramuestral de 209 semanas. Al momento de calcular la rentabilidad los costos de transacción no fueron considerados.
Por lo demás, con el objetivo de evitar el problema de data snooping3 (White, 2000) y de despejar las dudas respecto de si la capacidad predictiva se debe a la bondad del modelo, a las características de la muestra de observaciones a la que ha sido aplicado o sencillamente al factor suerte, se tomó el mejor modelo de proyección para cada valor (el de mayor PPS) y se lo evaluó sobre un total de cien conjuntos extramuestrales de 209 datos de cierre semanales cada uno. Estos cien conjuntos extramuestrales fueron generados a partir del conjunto extramuestral original utilizando un proceso de block bootstrap4.
4. RESULTADOS
Al desarrollar la estructura para el modelo multivariado dinámico optimizado con fuerza bruta, se utilizó la capacidad de un computador para realizar la evaluación de cada valor estudiado. La función del modelo multivariado dinámico consistió en evaluar cada coeficiente para cada variable considerada que aumente el PPS, quedándose al final de la evaluación con el mejor modelo.
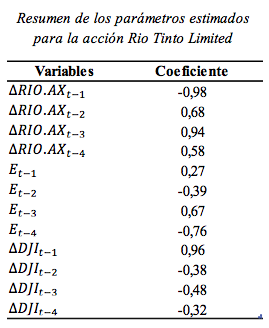
A continuación se presenta el mejor modelo multivariado dinámico, de acuerdo con el PPS:
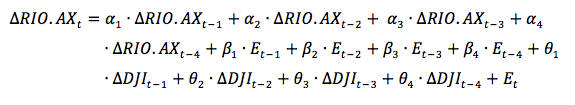
En la tabla 1 se muestran los mejores coeficientes α, β y θ obtenidos por el modelo que maximizan el PPS para el valor estudiado.
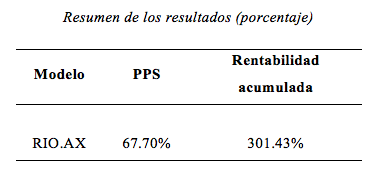
En la tabla 2 se muestra el mejor modelo multivariado dinámico optimizado con fuerza bruta arrojando un PPS de un 65.70% y su rentabilidad acumulada, que se obtiene al seguir las recomendaciones de compra y venta del modelo.
Esta capacidad predictiva, estimada en un conjunto extramuestral de 209 datos semanales, resultó estadísticamente significativa en cada uno de los valores, de acuerdo con la prueba de acierto direccional, comprobándose así la hipótesis de que sí existe capacidad predictiva en los modelos multivariados optimizados con fuerza bruta para el caso RIO.AX.
Tabla 1
Se pudo observar que la capacidad predictiva de los modelos se tradujo en beneficios económicos. Los modelos ARIMA construidos con fuerza bruta obtuvieron el PPS esperado superior al 60%. Además, independientemente de la significación estadística de la capacidad predictiva de los modelos, estos superaron en rentabilidad a la estrategia de inversión pasiva o buy and hold, la cual evidenció una rentabilidad negativa en cada uno de los valores analizados.
Tabla 2
Se probó la solidez de estos resultados a fin de evitar el problema de data snooping. Para ello, se tomó el mejor modelo de proyección para cada valor y se lo evaluó en un total de cien conjuntos extramuestrales de 209 datos de cierre semanales cada uno. Estos cien conjuntos extramuestrales fueron generados a partir del conjunto extramuestral original utilizando un proceso de block bootstrap.
Al analizar la rentabilidad acumulada que se habría obtenido siguiendo las recomendaciones de compra-venta del modelo multivariado dinámico, se encontró que de los cien conjuntos extramuestrales, estos superaron el rendimiento de una estrategia buy and hold en 301.43%
En este estudio, para la selección del mejor modelo multivariado dinámico del universo infinito de combinaciones, la computadora demoró cerca de ocho horas en conseguir el mejor resultado. Por lo tanto, se comprueba que utilizar fuerza bruta con un equipo de alta tecnología es un método altamente eficiente.
5. CONCLUSIONES
Es factible construir un modelo multivariado dinámico con una capacidad de predicción superior al 60% para la acción Rio Tinto Limited. Los modelos se construyeron con un millón de iteraciones bajo la técnica fuerza bruta, dado que la optimización por simplex y/o solver no alcanzó el resultado esperado.
El modelo multivariado dinámico elaborado a partir de las variables endógenas (precios históricos del valor) y exógenas (variación del valor del DJI) optimizado con fuerza bruta computacional, obtuvo una gran capacidad para predecir el signo de las variaciones semanales de los valores de la acción Rio Tinto Limited. Los resultados de la prueba de acierto direccional de Pesaran y Timmermann (1992) indicaron que el modelo presentó una capacidad predictiva estadísticamente significativa. A su vez, el modelo obtuvo la mayor rentabilidad acumulada en el periodo extramuestral con un 65.70% de PPS.
Al analizar la rentabilidad acumulada que se habría obtenido siguiendo las recomendaciones de compra-venta para modelo multivariado dinámico se encontró que, de los cien conjuntos extramuestrales, se superó el rendimiento de una estrategia buy and hold en 301.43%.
De esta manera, este estudio presenta evidencia empírica de que los modelos multivariados dinámicos optimizados con fuerza bruta computacional pueden ser utilizados como otra metodología para mejorar los modelos de proyección de series de tiempo en función de su capacidad de predicción de signo.
Se entiende como alcanzado el objetivo, por lo tanto este estudio y modelo puede ser útil para tomadores de decisiones o inversionistas de este sector.
6. REFERENCIAS
Arango, A., Velásquez, J., y Franco C. (2013). Técnicas de lógica difusa en la predicción de índices de mercados de valores: una revisión de literatura. Revista Ingenierías Universidad de Medellín, vol. 12, núm. 22, enero-junio, pp. 117-125.
Atsalakis, G. (2016). Using computational intelligence to forecast carbon prices. Grecia. Technical University of Crete, School of Production Engineering and Management, Chania, Crete. Applied Soft Computing Journal. Volume 43, 1 June 2016, Pages 107-116.
Pierdzioch C. (2015). Forecasting gold-price fluctuations: a real-time boosting approach. Alemania: Department of Economics, Helmut Schmidt University, Hamburg. Applied Economics Letters, 22 (1), pp. 46-50.
Shafiee, S. y Topal, E. (2010). An overview of global gold market and gold price forecasting. Australia. Resources Policy. Volume 35, Issue 3, September 2010, Pages 178-189.
Fama y French (1992). The Cross-Section of Expected Stock Returns. Journal of Finance, Vol. 47, Blackwell Publishing, Oxford.
Holland, John H. (1975). Adaptation in Natural and Artificial Systems, Ann Arbor, The University of Michigan Press.
Davis, Lawrence (1994). Genetic Algorithms and Financial Applications, in Deboeck, pp. 133-147.
Bauer, Richard J., Jr. (1994). Genetic Algorithms and Investment Strategies, John Wiley y Sons, Inc.
Kingdon, J., y K. Feldman (1995). Genetic Algorithms and Applications to Finance, Applied Mathematical Finance, vol. 2, num. 2, junio, pp. 89-116.
Pereira, R. (1996). Selecting Parameters for Technical Trading Rules Using Genetic Algorithms, Journal of Applied Finance and Investment, vol. 1, núm. 3, julio-agosto, pp. 27-34.
Allen, F., y R. Karjalainen (1999). Using Genetic Algorithms to Find Technical Trading Rules, Journal of Financial Economics, 51, pp. 245-271.
Kim, K., e I. Han (2000). Genetic Algorithms Approach to Feature Discretization in Artificial Neural Networks for the Prediction of Stock Price Index, Expert Systems with Applications, vol. 19, num. 2, agosto, pp. 125-132.
Feldman, K., y P. Treleaven (1994). Intelligent Systems in Finance, Appl. Mathematical Finance 1, pp. 195-207, Londres, Chapman & Hall.
Cepeda A. y Gonzáles G., (2009). Predicción de variaciones de precio en el mercado inmobiliario mediante autómatas celulares. Chile: Escuela de Ingeniería Comercial, Universidad de Chile, pág.28.
Martín del Brío, B. y Sanz, A. (1997). Redes neuronales y sistemas borrosos: Introducción, teórica y práctica. Primera Edición. Ra-ma, pág. 387.
Kuo y Reitsch, winter (1995-1996). Neural networks vs. conventional methods of forecasting, Journal of Business Forecasting 14, N° 4, pp. 17-22.
Herbrich et al. (2000). “Neural networks in economics: Background, aplications and new developments”. In T. Brenner, editor, Advances in Computacional Economics: Computational Techniques for Modeling Learning in Economics, volume 11, pages 169-196. Kluwer Academics.
Wilson, R. y Sharda, R. (1994). Bankruptcy prediction using neural networks. Decision Support Systems, Vol. 11, Nro. 5, pp. 545-557.
Tang, Z., De Almeida, C. y Fishwick, P. (1991). Times-series forecasting using neural networks vs. Box-Jenkins methodology. Simulation 57, pp. 303-310.
Durán, G. (2006). Investigación de operaciones, modelos matemáticos y optimización. Chile: Universidad de Chile. Obtenido de: http://old.dii.uchile.cl/~gduran/docs/charlas/ junaeb_willy_8.pdf
Riveros, D. (2015). Aplicación de la investigación de operaciones al problema de la distribución a una empresa logística. Lima: Universidad Nacional Mayor de San Marcos. Obtenido de: http://cybertesis.unmsm.edu.pe/bitstream/cybertesis/4365/1/Riveros_vd.pdf
Hernández, R., Fernández, C. y Baptista, M. (2010). Metodología de la investigación. México. McGraw W-Hill, pág. 261.
Qi, M. (2001). Predicting US recessions with leading indicators via neural networks models. International Journal of Forecasting, vol. 17, pp. 383-401.
Parisi, A. (2015). Modelo predictivo de precio accionario adoptando fuerza bruta. Documento de trabajo Programa Magíster Dirección de Empresas (MDE), Universidad del Bío- Bío, Chile. 7 pág.
Parisi, A., Parisi, F. y Guerrero, J. (2003). Modelos predictivos de redes neuronales en índices bursátiles. El Trimestre Económico, vol. LXX (4), núm. 280, octubre-diciembre, pp. 721-744.
Parisi, A., Parisi, F., y Díaz, D. (2006). Modelos de Algoritmos Genéticos y Redes Neuronales en la Predicción de Índices Bursátiles Asiáticos. Cuadernos de economía, 43(128), 251-284. https://dx.doi.org/10.4067/S0717-68212006000200002.
Pesaran, M. y Timmermann, A. (1992). A simple nonparametric test of predictive performance. Journal of business and economic statistics 10, pp. 461-165.
- Se usaron los valores de cierre semanales debido a que los administradores de fondos de inversión tienden a recomponer sus carteras en función de pronósticos semanales.
- Dow Jones Industrial es el índice que agrupa a las 30 empresas más grandes y representativas que transan en el mercado de EE.UU.
- El término data snooping (también conocido como data mining) “ocurre cuando un determinado conjunto de datos es usado más de una vez para propósito de inferencia o selección de modelos. Cuando esta reutilización de datos siempre existe la posibilidad de que cualquier resultado satisfactorio que se haya obtenido pueda deberse sencillamente a la suerte, en vez de algún mérito inherente al modelo que generó los resultados.”
- Una manera de probar la bondad de los modelos y la validez de sus resultados, independientemente de la muestra de datos a los que han sido aplicados, es utilizar un proceso de bootstrap. El bootstrap es un proceso de generación de observaciones ficticias a partir de datos históricos, a fin de resolver el problema de escasez de datos y, de este modo, obtener suficiente información para elaborar diferentes conjuntos extramuestrales en los cuales probar la validez de los modelos.