RESUMEN
La presente investigación es una continuación y actualización de las investigaciones en la materia que evalúa la eficacia de los modelos multivariados dinámicos optimizados con fuerza bruta para la empresa Tesla Inc. y su acción TSLA, con o sin un rezago adicional y tomando como variables exógenas: el índice bursátil NASDAQ y el factor conciencia. Se aplica modelo multivariado dinámico optimizado con fuerza bruta para predecir el comportamiento de sus cotizaciones a la semana siguiente de la última fecha analizada. El objetivo de esta investigación es determinar la mejor capacidad predictiva del modelo multivariado dinámico con variable exógena conciencia con o sin un rezago adicional como variable explicativa, dando como resultado un modelo estadísticamente significativo. Esta es una investigación de carácter exploratorio y correlacional. Se utilizó la información bibliográfica disponible para conocer las cotizaciones de la acción y el índice comprendidos en el periodo 25 de septiembre de 2012 – 25 de septiembre de 2017, pudiéndose observar la variación de una semana a otra y comparar los datos reales con las variaciones pronosticadas. La acción TSLA, elegida para este estudio, transa en bolsa y sus cotizaciones históricas se pueden obtener en Yahoo Finanzas. Se pudo determinar la factibilidad en la construcción de un modelo multivariado dinámico optimizado con fuerza bruta, con una capacidad de predicción superior a 60 por ciento e inferior a 70 por ciento según la literatura para la acción TSLA y, a su vez, determinar que el modelo que obtuvo la mejor capacidad fue cuya variable exógena es el factor conciencia. Esta continuación y actualización de los modelos multivariado dinámicos permite un gran avance a la inteligencia artificial en las finanzas.
Este estudio puede ser útil para todos aquellos actores del mundo financiero cuyo interés está en la solución del fenómeno de predicción del comportamiento de las acciones.
ABSTRACT
The present research is a continuation and update of the investigations in the matter that evaluates the effectiveness of the dynamic multivariate models optimized with brute force for the company Tesla Inc. and its action TSLA, with or without an additional lag and taking as exogenous variables: the NASDAQ stock index and the conscience factor. Dynamic optimized multivariate model with brute force is applied to predict the behavior of its quotes the week after the last date analyzed. The objective of this research is to determine the best predictive capacity of the dynamic multivariate model with exogenous variable consciousness with or without an additional lag as an explanatory variable, resulting in a statistically significant model. This is an investigation of an exploratory and correlational nature. The available bibliographic information was used to know the quotations of the share and the index comprised in the period September 25, 2012 to September 25, 2017, being able to observe the variation from one week to another and compare the real data with the forecasted variations. The TSLA action, chosen for this study, trades on the stock exchange and its historical quotes can be obtained in Yahoo Finance. It was possible to determine the feasibility in the construction of a dynamic optimized multivariate model with brute force with a prediction capacity of more than 60 percent and less than 70 percent according to the literature for the TSLA action and, in turn, to determine that the model obtained the best capacity was whose exogenous variable is the conscience factor. This continuation and update of the dynamic multivariate models allows a great advance to artificial intelligence in finance.
This study can be useful for all those actors in the financial world whose interest lies in solving the phenomenon of predicting the behavior of actions.
INTRODUCCIÓN
La predicción del comportamiento del mercado financiero para decisiones de inversión en sus distintos instrumentos (acciones, índices bursátiles, derivados, entre otros), es un tema que ha concentrado el interés de diversos actores, los cuales han desarrollado diversos modelos que buscan predecir el comportamiento del mercado, representando una solución para este fenómeno de situaciones futuras e inciertas. Y si bien a mayor riesgo mayor rentabilidad exigida, específicamente el modelo multivariado dinámico optimizado con fuerza bruta permite reducir el grado de incertidumbre que existe en el mercado financiero para decisiones de inversión.
La hipótesis de mercados eficientes (Fama, 1970) plantea que el mercado refleja completa y correctamente toda la información pertinente para la determinación de los precios de los activos. Debido a que el surgimiento de nueva información es de carácter aleatorio, los cambios de los precios accionarios también lo serían. Esto ha llevado a muchos analistas financieros y académicos a señalar que las fluctuaciones de los precios accionarios siguen en una caminata aleatoria (random walk), donde el concepto de aleatoriedad se refiere a que las variaciones de precios son generadas a partir de un cierto proceso estocástico. No obstante, varios estudios han concluido que existe evidencia significativa de que los precios accionarios no siguen una caminata aleatoria y muestran que los rendimientos accionarios son predecibles en algún grado (Parisi, Paris y Cornejo, 2004).
Tal como se señaló anteriormente, los comportamientos en el mercado son predecibles en alrededor de un 60 por ciento y 70 por ciento en la variación de signo (Fama y French, 1992) y según lo evidenciado en trabajos posteriores para algunos mercados (Parisi, Parisi y Díaz, 2006).
Dado este concentrado interés por parte de diversos actores, es que este estudio es una continuación y actualización de las investigaciones propuestas por Parisi, Parisi y Cornejo (2004), en la creación de modelos multivariados dinámicos sobre la base de algoritmos genéticos utilizando, como técinica alternativa, la fueza bruta computacional, agregando un rezago adicional como variable explicativa al modelo distribuido en sus variables independientes, comparando dos variables exógenas entre sí para determinar cuál permite que el modelo tenga mejor capacidad predictiva y optimizados con un método de fuerza bruta computacional que permitirá construir infinitos escenarios aleatorios, para así encontrar un coeficiente que maximice el porcentaje de predicción de signo, después de alcanzar la máxima capacidad de trabajo de un ordenador, ocupando como desarrollador del modelo el software Excel. Este estudio se centra en el comportamiento de la empresa tecnológica Tesla Inc. y su acción, TSLA, en el mercado de valores New York Stock Exchange (NYSE).
Producto de la base teórica del modelo multivariado dinámico (algoritmos genéticos), es que podemos entender que al agregar un rezago adicional como variable explicativa al modelo, se generarán una mayor cantidad de modelos o combinaciones que nos permitirían encontrar una mejor capacidad predictiva. En consecuencia, esta investigación busca agregar un rezago adicional 1 las variables independientes propuestas por el modelo multivariado dinámico (variables que expliquen el comportamiento de la acción TSLA) y así, maximizar las combinaciones que nos presentarían mejores capacidades predictivas de los modelos.
Además, en esta investigación se tomarán como variables exógenas el índice NASDAQ y el factor conciencia, los cuales serán utilizados respectivamente en la construcción de los modelos multivariados dinámicos, esperando que sea la variable conciencia la que produzca en el modelo una mejor capacidad predictiva. La definición de conciencia, propuesta por esta investigación, está enmarcada por el conocimiento de las rentabilidades del valor de estudio. El término conciencia en el área de la sicología es definido como la percepción y conocimiento de sí mismo que permita un estado de alerta en los acontecimientos que lo rodean (Alcaraz, V., Díaz, J., Pérez, R., Frixione, E., Flores, J. y Braunstein, N., 2007). Por lo tanto el factor conciencia en el modelo multivariado dinámico optimizado con fuerza bruta computacional, busca explicar el comportamiento del mismo valor de estudio por medio del conocimiento de las rentabilidades de este.
El concepto de técnica de fuerza bruta en mercados financieros fue utilizado como método predictor (Parisi, Amestica y Chileno, 2016), y es una continuación y desarrollo lógico de investigaciones anteriores basadas en autores como Arango, Velásquez y Franco (2013), quienes utilizan técnicas de lógica difusa para predecir índices accionarios; y Atsalakis (2016), quien innova en un modelo que busca predecir los precios del carbono usando inteligencia computacional. Asimismo, encontramos a Pierdzioch (2015), quien utiliza métodos artificiales para la predicción en la fluctuación del precio del oro, de manera muy parecida a los investigadores Shafiee y Topal (2010), quienes anteriormente tratan de prever el precio del oro. Según Parisi, Amestica y Chileno (2016), las técnicas antes mencionadas cada vez han ido mejorando en su capacidad predictiva gracias a los avances computacionales en velocidad y tratamiento de datos, lo cual no justifica buscar los llamados atajos y se hace atingente la no utilización de algoritmos en primera diferencia, siendo mejor usar directamente fuerza bruta en primera diferencia; es decir, las variables alcanzarían valores ceros si es que el coeficiente generado a través de números aleatorios llega a valor de cero.
Esta continuación y actualización de los modelos multivariados dinámicos permite un gran avance a la inteligencia artificial en las finanzas.
En esta investigación se realizarán, para la acción TSLA, dos modelos multivariados dinámicos optimizados con fuerza bruta computacional según cada variable exógena en estudio. Para la variable NASDAQ, el primer modelo multivariado dinámico será trabajado con un total de cuatro rezagos según lo evidenciado en Parisi, Parisi y Cornejo (2004), distribuidos en las variables independientes del modelo propiamente tal, totalizando 12 variables. El segundo modelo multivariado dinámico se trabajará agregando un rezago adicional para cada variable independiente propia del modelo, totalizando 15 variables.
El modelo multivariado dinámico para la acción TSLA con variable exógena conciencia entregará la mejor capacidad de predicción de signo con o sin un rezago adicional como variable explicativa al modelo optimizado con fuerza bruta computacional, siendo así estadísticamente significativo.
Todos los modelos fueron construidos con 1.000.000 de iteración optimizados con fuerza bruta computacional.
REVISIÓN DE LA LITERATURA
Se realizará una revisión literaria atingente a este estudio desarrollando conceptos fundamentales para una mejor comprensión de esta investigación.
Mercado accionario
Bolsa de valores
La gente compra y vende acciones en una bolsa de valores. Una bolsa de valores es un mercado organizado en el que la gente puede comprar y vender valores. En Estados Unidos las acciones de las principales corporaciones se negocian en la bolsa de Valores de Nueva York (NYSE, New York Stock Exchange). Las acciones de las empresas de alta tecnología se negocian en el sistema Cotización Automática de la Asociación Nacional de Negociantes de Títulos (NASDAQ, National Asociación of Securities Dealers Automated Quotation) (Parkin, 2004).
Acción en la bolsa de valores
Una acción es un valor que una empresa emite para certificar que el tenedor de las acciones posee una parte de la empresa. El valor del conjunto de acciones de una empresa se denomina “capital propio”. Los términos “acciones” y “participaciones” con frecuencia se usan indistintamente.
Un accionista tiene una responsabilidad limitada, lo que significa que si la empresa no puede pagar todas sus deudas, la responsabilidad de un accionista por las deudas de la empresa está limitada al monto invertido en la empresa por ese accionista. Por ejemplo, cuando Enron colapsó sus accionistas perdieron todo lo que habían invertido en el conjunto de acciones de la empresa, pero no fueron obligados a contribuir con nada para saldar las deudas pendientes de Enron.
Los accionistas reciben un dividendo; es decir, una parte de los beneficios de la empresa, en proporción a sus tenencias de acciones. Por ejemplo, los tenedores de acciones de PepsiCo recibieron un dividendo de 58 centavos de dólar por acción durante 2002.
Las empresas emiten dos tipos de acciones: Acciones preferentes y Acciones ordinarias o comunes.
Las acciones preferentes dan derecho a su propietario a recibir un dividendo previamente acordado antes de que se paguen los dividendos de las acciones ordinarias y a reclamar primero los activos de la empresa en caso de que sea liquidada.
Los tenedores de acciones ordinarias tienen el derecho de recibir una parte de los activos e ingresos de la empresa y a votar (un voto por acción mantenida) en la elección de los directores de la empresa.
Cuando una empresa emite acciones, el comprador de la acción invierte directamente en la empresa. En marzo de 1986, Microsoft Corporation emitió 161 millones de acciones ordinarias, a 21 dólares por acción, y recaudó un total de 3.400 millones de dólares, por parte de los compradores.
La mayoría de los accionistas no compra acciones directamente a la empresa que las emite, sino a otros tenedores que a su vez compraron las acciones a otros tenedores. En un día promedio, durante los últimos 10 años, 14 millones de acciones de Microsoft han cambiado de dueño. Microsoft no recibió nada de estas transacciones y ni siquiera lleva un registro de quién posee sus acciones. Microsoft contrata a otra empresa, Mellon Investor Services, para realizar ese trabajo y emitir certificados de acciones (Parkin, 2004).
NASDAQ
De acuerdo con la página oficial del NASDAQ este término significa “National Association of Securities Dealers Automated Quotation” o en español, “Asociación Nacional de Agentes Operadores de Acciones Según Cotizaciones Automáticas”. Es un mercado global que vende y compra acciones de compañías a través de Internet; es decir, una bolsa de valores que no utiliza intermediarios, sino que todas las transacciones se hacen en línea para mayor seguridad.
Además es la bolsa más grande del planeta, debido a que opera en 24 mercados distribuidos en todo el mundo y cuenta con cámaras y depósitos de seguridad, lo cual permite tener el mayor volumen de intercambio de acciones por hora. También cuenta con importantes índices que permiten conocer los estados en que se encuentran las economías de diversas empresas y naciones.
El NASDAQ tiene sus propios índices:
– Índice NASDAQ-100: incluye cien de las empresas más grandes que se encuentran listadas en esta bolsa basada en el volumen de venta que presentan las acciones de dichas compañías. Este índice refleja a aquellas empresas dedicadas a las telecomunicaciones, hardware y software, pero no contiene compañías financieras o que se dediquen a inversiones puramente.
– Índice NASDAQ Composite: es el grupo de acciones que se encuentran listadas dentro de esta bolsa electrónica e incluye a más de 3 mil compañías sin importar el giro. En este se pueden incluir compañías financieras y de inversiones así como de tecnología en general.
– Índice NASDAQ de Biotecnología: lista de las empresas farmacéuticas y de biotecnología que estén listadas dentro del NASDAQ Composite. Es requisito que las compañías que se quieran sumar a este índice coticen únicamente dentro del NASDAQ y tener una operatividad superior a las 100 mil acciones.
En síntesis, esta bolsa electrónica de valores fue creada para realizar el intercambio de acciones con mayor trasparencia y seguridad, además de estar regulada por el gobierno de Estados Unidos y en operación por más de tres décadas (Nasdaq.com, 2017).
Tesla Inc.
Tesla Inc. es una compañía estadounidense de vehículos 100% eléctricos, con enfoque premium. Su sede está en Palo Alto, California, EE. UU.
La creación de Tesla se remonta al año 2003, cuando la compañía AC Propulsion decidió unir a sus dos grupos de trabajo para el desarrollo conjunto de vehículos eléctricos. En uno de estos equipos se encontraba Elon Musk quien, junto a JB Straubel y Martin Eberhard, fundaron Tesla Motors.
La empresa, que inició sus operaciones gracias fundamentalmente a las inversiones del propio Musk, comenzó su andadura con varias rondas de financiación con el fin de recaudar suficiente dinero para iniciar la producción de un vehículo deportivo 100% eléctrico. Tras un arduo proceso en el que Tesla estuvo a punto de desaparecer debido a los problemas económicos, en 2008 inició la producción del Roadster, un descapotable biplaza con carrocería de Lotus, del que se han vendido más de 2.200 unidades.
El 29 de junio de 2010 Tesla Motors inició su andadura en Bolsa, concretamente en el índice NASDAQ, bajo el acrónimo TSLA, con un precio por acción de 17 dólares americanos. Actualmente este valor se ha multiplicado casi por 20.
Además de fabricar sus propios vehículos, Tesla actúa también como suministrador de componentes originales para diferentes marcas de automóviles. De hecho, algunas de ellas se han convertido en sus socios, como Daimler, propietaria del 10% de sus acciones, o Toyota, que adquirió en 2010 casi 3 millones de acciones de Tesla tras desembolsar 50 millones de dólares.
Tras la llegada de modelos más «convencionales», como el Model S o el Model X, Elon Musk anunció la llegada de un nuevo modelo más compacto y asequible, denominado Model 3. A la venta desde mediados de 2017, esta berlina compacta con autonomía superior a los 350 km recibió cientos de miles de reservas en cuestión de días, marcando un nuevo hito en la historia de la marca.
Tesla Inc. no pertenece a ningún grupo, sino que es una gran empresa que se dedica, fundamentalmente, al negocio de la automoción, aunque cada vez está desarrollando más tecnología para ámbitos de trabajo o domésticos.
A día de hoy Tesla no cuenta con ninguna otra marca dentro de su grupo empresarial. Pese a ello, el fabricante estadounidense es una compañía cotizada en bolsa bajo el acrónimo TSLA en el índice NASDAQ, superando incluso la capitalización de Ford Motor Company (Motor, 2017).
Modelos de predicción de precios
Este apartado contiene una breve reseña sobre algoritmos genéticos. Junto con esto se realizará también una breve reseña de los modelos multivariados dinámicos.
Algoritmos genéticos
Los algoritmos genéticos, establecidos por Holland (1975), consisten en una función matemática o una rutina que simula el proceso evolutivo de las especies, teniendo como objetivo encontrar soluciones a problemas específicos de maximización o minimización 2. Así, el algoritmo genético recibe como entrada una generación de posibles soluciones para el problema de que se trate, y arroja como salida los especímenes más aptos (es decir, las mejores soluciones) para que se apareen y generen descendientes, los que deberían tener mejores características que las generaciones anteriores.
Los algoritmos genéticos trabajan con códigos que representan a cada una de las posibles soluciones al problema. Por ello, es necesario establecer una codificación para todo el rango de soluciones, antes de comenzar a utilizar el algoritmo. Al respecto Davis (1994) señala que la codificación más utilizada es la representación de las soluciones por medio de cadenas binarias (conjuntos de ceros y unos).
Según Bauer (1994), este método puede ser utilizado fácilmente en aplicaciones financieras. Davis (1994) muestra una aplicación de algoritmos genéticos en la calificación de créditos bancarios que resultan mejor que otros métodos, como las redes neuronales, debido a la transparencia de los resultados obtenidos. Kingdon y Feldman (1995) usaron algoritmos genéticos para hallar reglas que pronosticaran la bancarrota de las empresas, estableciendo relaciones entre las distintas razones financieras. Bauer (1994), utilizó algoritmos genéticos para desarrollar técnicas de transacción que indicaran la asignación mensual de montos de inversión en dólares y marcos. Pereira (1996) los utilizó para encontrar los valores óptimos de los parámetros usados por tres reglas de transacción distintas para el tipo de cambio dólar estadunidense/dólar australiano: los parámetros obtenidos mostraron resultados intramuestrales positivos, los cuales disminuyeron al aplicar las reglas fuera de la muestra, aun cuando continuaron siendo rentables. Allen y Karjalainen (1999) usaron algoritmos genéticos para aprender reglas de transacción para el índice S&P 500 y emplearlas como un criterio de análisis técnico y, una vez cubiertos los costos de transacción, encontraron que el exceso de rendimiento calculado sobre una estrategia buy and hold, durante el periodo de prueba extramuestral, no era congruente. No obstante, y a diferencia de Allen y Karjalainen (1999), en este artículo se analiza la capacidad de los modelos elaborados por medio de algoritmos genéticos para proyectar el signo de las variaciones semanales de los índices bursátiles ya señalados y, en función de estas proyecciones, desarrollar estrategias de transacción. Kim y Han (2000) mostraron que los algoritmos genéticos pueden ser usados para reducir la complejidad y eliminar factores irrelevantes, lo que resultó mejor que los métodos tradicionales para predecir un índice de precios accionario.
Por otra parte, Feldman y Treleaven (1994) señalaron que la mayor desventaja de los algoritmos genéticos es la dificultad que presentan para escoger una técnica de codificación manejable, y para determinar el tipo de selección y las probabilidades de los operadores genéticos, ya que no hay reglas fijas en esta materia (Parisi, Parisi y Cornejo, 2004).
Modelo multivariado dinámico
Los modelos multivariados dinámicos utilizados son modelos de series de tiempo que expresan el comportamiento de una variable en función de sus valores rezagados, de rezagos de variables exógenas y de rezagos de los residuos del modelo.
Test de Acierto Direccional de Pesaran y Timmermann (DA)
El test de Acierto Direccional de Pesaran y Timmermann mide la capacidad de predicción de los modelos de Redes Neuronales, permitiendo medir la significancia estadística de los modelos y su capacidad de predicción.
El test DA tiene como supuesto que los valores obtenidos de la aplicación de este test se distribuyen según una función normal, por lo tanto, los puntos críticos con un 95% de confianza son [-1,96; +1,96]. Este intervalo representa la zona de no rechazo de la hipótesis nula “”; si se rechaza la hipótesis nula, entonces se probará que los resultados obtenidos no son producto del azar, tal como se presenta en el siguiente gráfico:
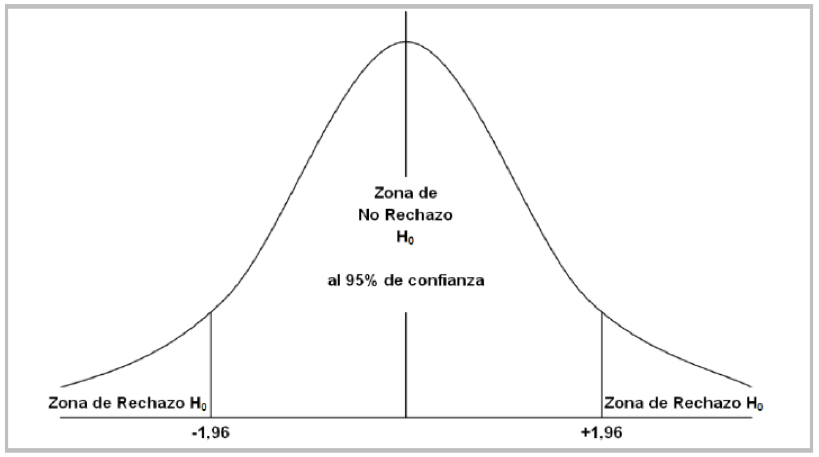
El test DA establece como Hipótesis Nula () que las variaciones proyectadas por el modelo están independientemente distribuidas de las variaciones observadas reales; por lo tanto, si al calcular el test DA para los modelos de predicción de las variaciones de signo para la siguiente semana obtenemos un valor observado que se encuentra fuera de los rangos críticos antes señalados, ya sean al 95% o al 90%, entonces se rechaza la Hipótesis Nula y se dice que el modelo “tiene capacidad de predicción”.
El test de Pesaran y Timmermann evalúa los aciertos predictivos del modelo a través del cálculo de SR, que es igual al valor del PPS del modelo; es decir, SR = PPS, y los compara con los aciertos que se obtendrían, denominados en la formula SRI, cuando las observaciones reales y las proyecciones del modelo están independientemente distribuidas (Jaque, 2014).
La fórmula para el cálculo del test DA de Pesaran y Timmermann, es la siguiente:

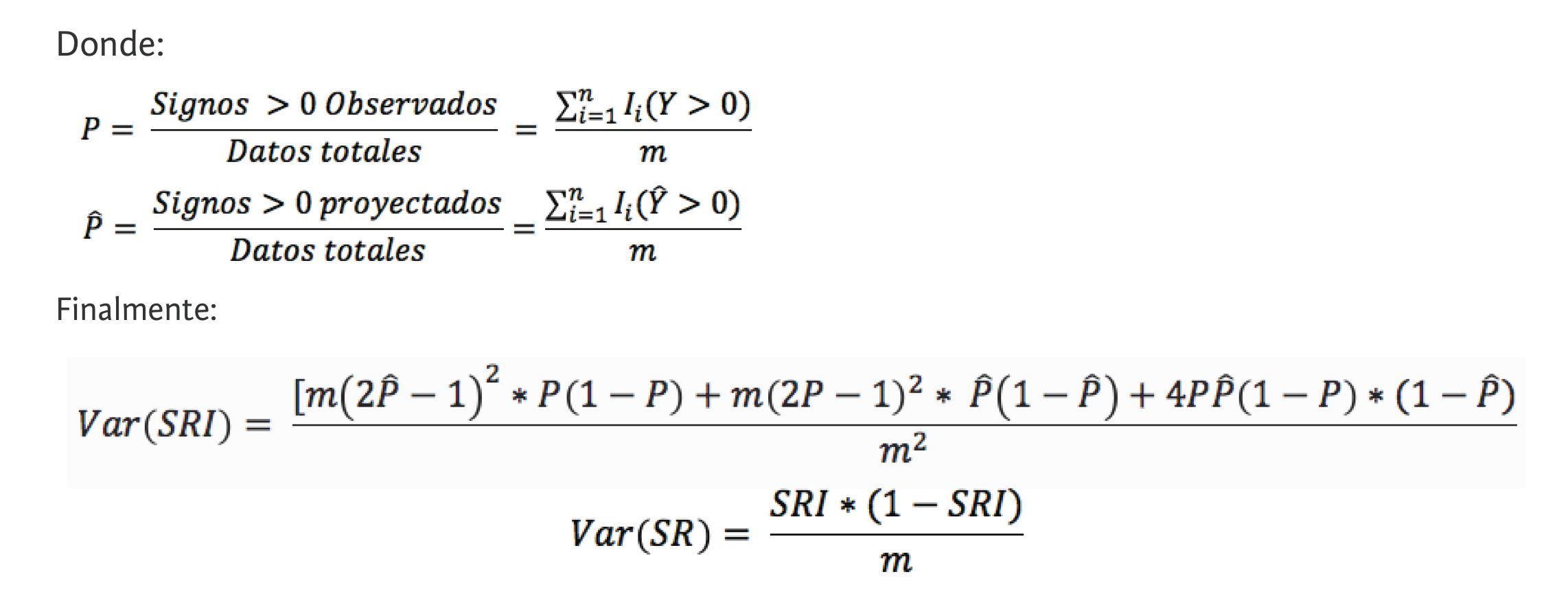
Inteligencia artificial
El nacimiento de la Inteligencia Artificial como disciplina de investigación se remonta a 1956, durante una conferencia sobre informática teórica que tuvo lugar en el Darmouth College (Estados Unidos). A esa conferencia asistieron algunos de los científicos que posteriormente se encargaron de desarrollar la disciplina en diferentes ámbitos y de dotarla de una estructura teórica y computacional apropiada. Entre los asistentes estaban John McCarthy, Marvin Minsky, Allen Newell y Herbert Simon. En la conferencia, A. Neweel y H. Simon presentaron un trabajo sobre demostración automática de teoremas al que denominaron “Logic Theorist”. El Logic Theorist fue el primer programa de ordenador que emulaba características propias del cerebro humano, por lo que es considerado el primer sistema de inteligencia artificial de la historia. El sistema era capaz de demostrar gran parte de las teorías sobre lógica matemática que se presentaban en los tres volúmenes de los Principia Mathematica de Aldred N.Whitehead y Bertrand Russell (1910 -1913).
En 1954 apareció el IBM 704, la primera computadora de producción en cadena, y con ella se desarrollaron numerosos lenguajes de programación específicamente diseñados para implementar sistemas de inteligencia artificial. Junto con estos avances se produjeron los primeros intentos para determinar la presencia de comportamiento inteligente en una máquina. El más relevante desde el punto de vista histórico fue propuesto por Alan Turing en un artículo de 1950 publicado en la revista Mind y titulado “Computing Machinery and Intelligence”. En aquel trabajo se propuso un test de inteligencia para máquinas, según el cual una máquina presentaría un comportamiento inteligente en la medida en que fuese capaz de mantener una conversación con un humano sin que otra persona pueda distinguir quién es el humano y quién el ordenador. Aunque el test de Turing ha sufrido innumerables adaptaciones, correcciones y controversias, puso de manifiesto los primeros intentos de alcanzar una definición objetiva de la inteligencia. En resumen, hoy en día el objetivo principal de la inteligencia es el tratamiento y análisis de datos (Benítez, Escudero, Kanaan y Rodó, 2013).
La Inteligencia Artificial se puede definir como una ciencia que tiene como objetivo el diseño y construcción de máquinas capaces de imitar el comportamiento inteligente de los seres humanos. Una rama especializada de la informática que investiga y produce razonamiento por medio de máquinas automáticas y que pretende fabricar artefactos dotados de la capacidad de pensar. Ahora bien, lo específico de esta nueva ciencia estriba en el uso de la analogía del ordenador no solamente como método de trabajo e investigación sino también de interpretación de la realidad. Esta orientación ha hecho posible el surgimiento de una nueva rama del saber, denominado Ciencias Cognitivas 3, que tienen como objetivo específico de estudio el análisis y la experimentación sobre el conocimiento visto como un proceso de adquisición, codificación, manipulación, producción y transferencia de una nueva información (Munárriz, 1994).
Revolución Industrial 4.0
A finales del siglo XVII fue la máquina de vapor. Esta vez, serán los robots integrados en sistemas ciber físicos los responsables de una transformación radical. Los economistas le han puesto nombre: la Cuarta Revolución Industrial. Marcada por la convergencia de tecnologías digitales, físicas y biológicas, anticipan que cambiará el mundo tal como lo conocemos.
¿Suena muy radical? Es que, de cumplirse los vaticinios, lo será. Y está ocurriendo, dicen, a gran escala y a toda velocidad. “Estamos al borde de una revolución tecnológica que modificará fundamentalmente la forma en que vivimos, trabajamos y nos relacionamos. En su escala, alcance y complejidad la transformación será distinta a cualquier cosa que el género humano haya experimentado antes, vaticina Klaus Schwab, autor del libro La cuarta revolución industrial (2016).
Lo importante, destacan los teóricos de la idea, es que no se trata de desarrollos, sino del encuentro de esos desarrollos. Y en ese sentido representa un cambio de paradigma, en lugar de un paso más en la carrera tecnológica frenética.
“La Cuarta Revolución Industrial no se define por un conjunto de tecnologías emergentes en sí mismas, sino por la transición hacia nuevos sistemas que están construidos sobre la infraestructura de la revolución digital (anterior)”, dice Schwab, que es director ejecutivo del Foro Económico Mundial (WEF, por sus siglas en inglés) y uno de los principales entusiastas de la “revolución”.
“Hay tres razones por las que las transformaciones actuales no representan una prolongación de la tercera revolución industrial, sino la llegada de una distinta: la velocidad, el alcance y el impacto en los sistemas. La velocidad de los avances actuales no tiene precedentes en la historia. Y está interfiriendo en casi todas las industrias de todos los países”, apunta el WEF.
También llamada 4.0., la revolución sigue a los otros tres procesos históricos transformadores: la primera marcó el paso de la producción manual a la mecanizada, entre 1760 y 1830; la segunda, alrededor de 1850, trajo la electricidad y permitió la manufactura en masa. Para la tercera hubo que esperar a mediados del siglo XX, con la llegada de la electrónica y la tecnología de la información y las telecomunicaciones. Ahora, el cuarto giro trae consigo una tendencia a la automatización total de la manufactura. Su nombre proviene, de hecho, de un proyecto de estrategia de alta tecnología del gobierno de Alemania, sobre el que trabajan desde 2013 para llevar su producción a una total independencia de la mano de obra humana.
Los países más avanzados son los que encarnarán los cambios con mayor rapidez, pero a la vez los expertos destacan que son las economías emergentes las que podrán sacarle mayor beneficio.
La Cuarta Revolución tiene el potencial de elevar los niveles de ingreso globales y mejorar la calidad de vida de poblaciones enteras, apunta Schwab, las mismas que se han beneficiado con la llegada del mundo digital (y la posibilidad, por caso, de hacer pagos, escuchar música o pedir un taxi un celular ubicuo y barato). Sin embargo, el proceso de transformación solo beneficiará a quienes sean capaces de innovar y adaptarse (Perasso, 2016).
Conciencia
El fenómeno de la conciencia, el “darse cuenta” de nuestro entorno, ha atosigado a los estudiosos continuamente. En la sicología, la conciencia consiste en un conjunto de representaciones más o menos icónicas de los objetos que son captados primordialmente por la vista. Cada ser humano adulto, perteneciente a la cultura occidental de nuestros días, se atribuye la capacidad de tener conciencia, le parece completamente natural la posibilidad de percatarse de la existencia de las cosas. Por analogía respecto de sus propias sensaciones tiende a proyectar hacia sus congéneres, de no importa que época, ese ser consciente. La proyección de conciencia se hace igualmente hacia los animales, aunque no a todos, sino únicamente a los más cercanos a nosotros (Alcaraz y otros, 2007).
Conciencia, además, es el elemento que nos permite relacionarnos con nuestra realidad interna, el mundo que nos rodea. Estructuras diferentes de conciencia producirán diferentes percepciones de todas esas realidades, y diferentes maneras de obrar sobre ellas. Lo que nunca sabremos es cómo serían esas realidades sin nuestra conciencia.
Inspirados por una filosofía materialista y determinista, algunos científicos buscan las bases materiales de la conciencia. Se preguntan, por ejemplo, cómo señales electroquímicas se combinan para originar acontecimientos mentales. Intentan relacionar diferentes estructuras del cerebro con etapas en nuestra evolución como especie (Kamenetzky, 1999).
Siendo la conciencia uno de los aspectos más familiares de nuestra experiencia cotidiana, es también uno de los más enigmáticos. El problema de la conciencia; es decir, qué es la conciencia y cuál es su lugar en la naturaleza; es estudiado hoy por múltiples disciplinas, desde la filosofía a la sicología, pasando por la neurología, entre muchas otras (Medina, 2015).
La computadora como metáfora de la conciencia
Podemos usar el modo de funcionar de una computadora como una metáfora de los roles que las tres partes juegan en la estructura de nuestra conciencia.
– El consciente: que es el procesador lógico de la información exterior, los sentimientos interiores, los valores, creencias socialmente programadas y los mensajes inconscientes, se puede comparar con la RAM 4.
– El subconsciente: es como un disco en el que la sociedad registra programas de valores, creencias y conductas, y donde se almacena el conocimiento autoadquirido y el transmitido por los demás. Todos estos “bytes” de información los recupera el operador individual a medida que los necesita, cuando trabaja con la memoria RAM.
– El inconsciente: se puede comparar con el ROM 5, memoria de lectura solamente, en la que el creador almacena los procedimientos operativos inherentes a una condición que es común a todos los seres humanos: la de ser criaturas de la Naturaleza.
Según nuestro particular sistema de creencias a este creador lo llamamos Dios, Naturaleza, conciencia cósmica o espíritu universal (Kamenetzky, 1999).
METODOLOGÍA
En este capítulo se presenta la metodología que permitió desarrollar el estudio. Se muestran aspectos como el tipo de investigación, técnicas y procedimientos que fueron utilizados para llevar a cabo este estudio.
Tipo de investigación y diseño
Se ha establecido como una investigación con características exploratorias al no haberse construido hasta ahora un modelo multivariado dinámico optimizado con fuerza bruta computacional con variables exógenas: índice bursátil NASDAQ y el factor conciencia, para obtener un porcentaje de predicción de signo sobre la acción TSLA.
También se ha establecido como una investigación con características correlacionales, ya que se utiliza la relación del precio en un periodo t explicada por sí misma en las observaciones o datos pasados para proyectar la variación del signo que tiene el valor estudiado.
Población y muestra
La población para el estudio serán las cotizaciones de la acción TSLA y del índice bursátil NASDAQ que operan en la bolsa de Nueva York. Para la variable conciencia la población para el estudio serán las predicciones obtenidas por el modelo multivariado dinámico de la acción Tesla Inc.
La muestra para este estudio serán los precios de cierre semanales para la acción TSLA y del índice bursátil NASDAQ, que corresponderán al periodo del 25 de septiembre de 2012 al 25 de septiembre de 2017. Se usaran los valores de cierre semanales debido a que los administradores de fondo de inversión tienden a recompensar sus carteras en función de pronósticos semanales. Para la variable conciencia, la muestra para este estudio serán los promedios de las predicciones de rentabilidad en tomas de diez datos rezagados al último valor observado.
Instrumentos de recolección de datos
Por la naturaleza de este estudio se utilizó recopilación documental o datos secundarios, que implica la revisión de documentos, registros públicos y archivos físicos o electrónicos (Hernández, Fernández y Baptista, 2010). Por lo tanto, para obtener las cotizaciones históricas y rentabilidades se ha buscado por los nemotécnicos de cada índice bursátil en la página de internet Yahoo Finanzas, totalizando 262 observaciones por variable.
A continuación se presentarán el nombre de la acción y del índice bursátil y sus nemotécnicos correspondientes:
– Tesla Inc.: TSLA
– National Association of Securities Dealers Automated Quotation: NASDAQ
Criterios de inclusión
– Cotizaciones históricas índice bursátil NASDAQ.
– Cotizaciones históricas de la acción TSLA.
– Predicciones de rentabilidad en tomas de diez datos rezagados.
– Precios de cierre del índice bursátil NASDAQ tranzado semanalmente dentro del periodo de estudio.
– Precios de cierre de la acción TSLA tranzado semanalmente dentro del periodo de estudio.
– Precios de cierre y de apertura semanales de la acción TSLA dentro del periodo de estudio.
– El periodo de estudio comprende entre el 25 de septiembre de 2012 y el 25 de septiembre de 2017.
Procedimientos
A continuación se explica la manera de recolectar los datos e información utilizada en este estudio.
Recolección de datos
Las cotizaciones históricas de la acción TSLA y del índice bursátil NASDAQ fueron obtenidos de la página de internet Yahoo Finanzas.
En la plataforma Yahoo Finanzas podemos encontrar las cotizaciones históricas de las acciones que se tranzan en la bolsa de Nueva York, así como también los índices bursátiles. Estos datos pueden ser recolectados con una frecuencia diaria, semanal y mensual. Para este estudio la frecuencia que se utilizará será semanal, que comprende entre el 25 de septiembre de 2012 y el 25 de septiembre de 2017, con un total de 262 observaciones por cada índice mencionado.
Análisis estadísticos
Se construyó un modelo multivariado dinámico optimizado con fuerza bruta computacional para efectos de evaluar su poder predictivo para frecuencias semanales. De esta forma se buscó determinar el comportamiento del modelo en su función predictiva para conocer la variación del signo para el valor en estudio.
El planteamiento de la técnica fuerza bruta utilizado en Parisi, Amestica y Chileno (2016), tiene como objetivo encontrar los coeficientes óptimos que maximicen el porcentaje de predicción de signo de las variaciones semanales de las cotizaciones para el valor en estudio.
Los modelos multivariados dinámicos utilizados son modelos de series de tiempo que expresan el comportamiento de una variable en función de sus valores rezagados, de variables exógenas rezagadas y de los rezagos de los residuos (errores) del modelo. Las variables exógenas incluidas en la estructura de los modelos multivariados dinámicos son: Índice Bursátil NASDAQ, al considerarse como un indicador líder de las empresas tecnológicas que muestra el comportamiento de estas en los mercados bursátiles internacionales; y el factor conciencia propuesto en esta investigación, que está enmarcado por el conocimiento de los promedios de las predicciones de rentabilidad en tomas de diez datos rezagados al último valor observado de la acción TSLA.
Las estructuras de los modelos multivariados dinámicos utilizados para predecir la variación del signo de las fluctuaciones semanales de las cotizaciones de la acción TSLA con variable exógena NASDAQ (1) y fluctuaciones semanales de las cotizaciones de la acción TSLA con variable exógena conciencia (2), se presentan en las siguientes ecuaciones respectivamente.
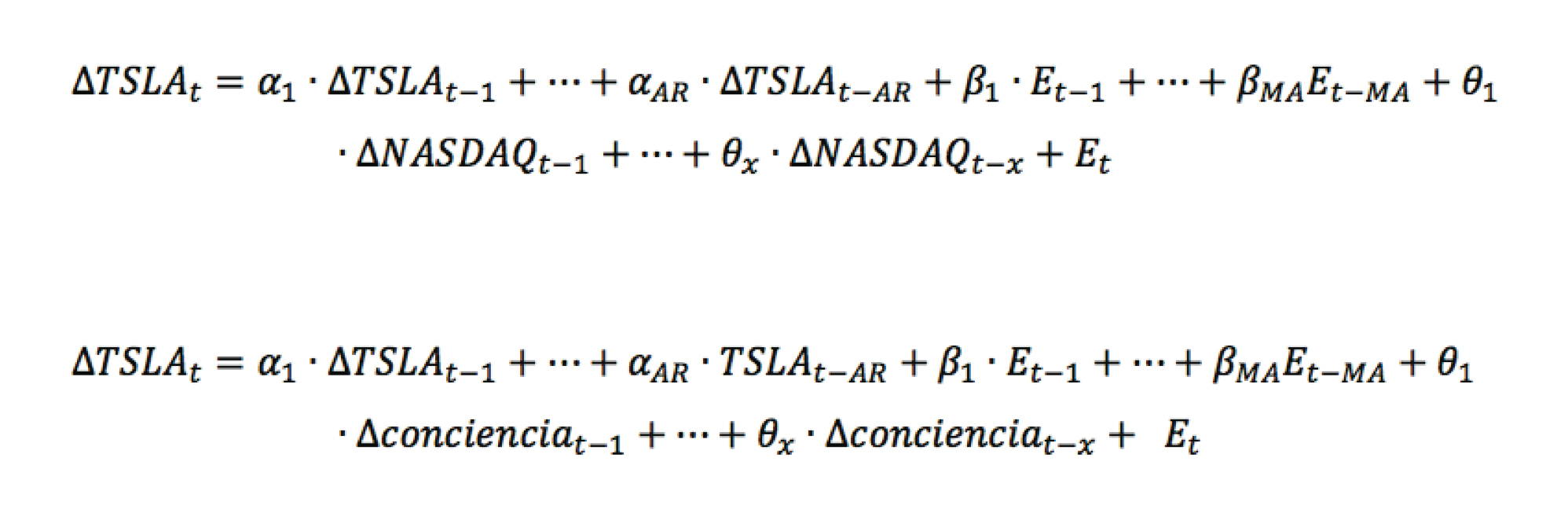
En los que corresponde al término de error del modelo; NASDAQ a las cotizaciones del índice National Association of Securities Dealers Automated Quotation y TSLA a las cotizaciones de la acción Tesla Inc. El factor conciencia que corresponde a los promedios de las predicciones de rentabilidad en tomas de diez datos rezagados al último valor observado de la acción TSLA. Los subíndices AR, MA y X, que representan el máximo orden de rezagos de las variables independientes, y los coeficientes α, β y θ son los coeficientes mejor adaptados que de acuerdo con su valor le dan un peso determinado, por el modelo, a las variables. Estos últimos indican qué tanto afectan las variables incluidas en la variación del signo en el precio del valor en estudio.
Para los términos AR, MA y X, se trabajó en primera instancia con un máximo de cuatro rezagos, totalizando un máximo total de 12 variables. Al agregar un rezago adicional como variable explicativa, se trabajó para los términos AR, MA y X con un máximo de cinco rezagos, totalizando un máximo de 15 variables. Según las matemáticas binarias, una cadena de largo L permite representar 2L soluciones posibles. Es por esto que cada variable fue representada por un bit resultando el largo de la cadena binaria igual al máximo de variables del modelo. Por lo tanto, en primera instancia contamos con un total de 4.096 posibles modelos para predecir el comportamiento del valor estudiado y 32.768 posibles modelos cuando se agrega un rezago adicional como variable explicativa.
Evaluación de la predicción
El siguiente paso consiste en evaluar la calidad de cada modelo en función del porcentaje de predicción de signo alcanzado (PPS). La evaluación se realizó sobre la base de un conjunto extramuestral de 260 datos semanales para el modelo con variable exógena NASDAQ y 109 datos semanales para el modelo con variable exógena conciencia, por medio de un proceso recursivo. La recursividad ha sido empleada para medir el desempeño de modelos de redes neuronales que buscan predecir periodos de recesión en los Estados Unidos (Qi, 2001; Estrella y Mishkin, 1998), y para proyectar el signo de las variaciones de índices bursátiles internacionales (Parisi, Parisi y Guerrero, 2003; Parisi, Parisi y Cornejo, 2004; Parisi, Parisi y Díaz, 2006). Se utilizó la muestra total tanto para estimar los coeficientes α, β y θ de cada modelo respectivamente, por medio de la minimización de la suma del cuadrado de los residuos del modelo, como para evaluar la capacidad predictiva de los modelos. Para realizar esto se comparó el signo de la proyección con el signo de la variación observada en cada i-ésimo periodo, en el que i = 1, 2,…, m. Si los signos entre la proyección y el observado coinciden, entonces aumentan la efectividad del modelo analizado y, en caso contrario, disminuye su capacidad predictiva.
Una vez proyectado el signo de la variación del precio para el periodo n + 1, la variación observada correspondiente se incluye en la muestra de tamaño de n con objeto de reestimar los coeficientes del modelo, contando ahora con una observación más. Así, el mismo modelo pero con sus coeficientes recalculados es utilizado para realizar la proyección correspondiente al periodo n + 2. Este procedimiento recursivo se efectuó una y otra vez hasta acabar con las observaciones del conjunto extramuestral. Finalmente, el PPS de cada modelo se calculó de la siguiente forma:

Evaluación estadística
En esta etapa se aplicó la prueba de acierto direccional de Pesaran y Timmermann (1992), con el objetivo de medir la significancia estadística de la capacidad predictiva de cada uno de los modelos analizados.
La fórmula para el cálculo del test DA de Pesaran y Timmermann, es la siguiente:

Luego, para analizar si la capacidad predictiva de los modelos se traduce en beneficios económicos, se calculó la rentabilidad acumulada que se habría obtenido si se hubiese comprado o vendido los valores en estudio siguiendo las recomendaciones de compra-venta del modelo de predicción. Para ello, la proyección de una variación positiva de los precios (un alza del mercado) fue interpretada como una señal de compra, mientras que el pronóstico de una variación negativa (una caída del mercado) fue interpretado como una señal de venta. Se supuso una inversión inicial de cien mil dólares y la rentabilidad acumulada se calculó sobre un conjunto extramuestral de 260 semanas para el modelo con variable exógena NASDAQ y 109 semanas para el modelo con variable exógena conciencia. Al momento de calcular la rentabilidad, los costos de transacción no fueron considerados.
Por lo demás, con el objetivo de evitar el problema de data snooping, y de despejar las dudas respecto de si la capacidad predictiva se debe a la bondad del modelo, a las características de la muestra de observaciones a la que ha sido aplicado o sencillamente al factor suerte, se tomó el mejor modelo de proyección para cada valor (el de mayor PPS) y se lo evaluó sobre un total de cien conjuntos extramuestrales de 260 o 109 datos de cierre semanales según la variable exógena de cada modelo respectivamente. Estos cien conjuntos extramuestrales fueron generados a partir del conjunto extramuestral original, utilizando un proceso de block bootstrap 6.
RESULTADOS
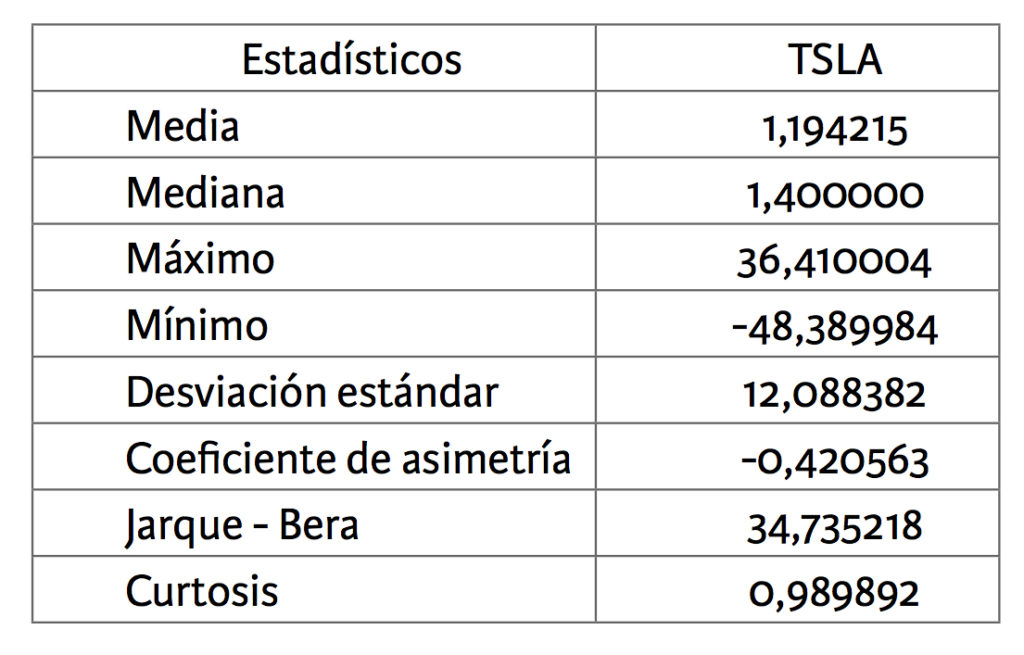
El análisis de la serie de valores de cierre, en primera diferencia, de la acción TSLA arrojó que el coeficiente de asimetría es negativo, por lo que la distribución presenta valores que tienden a agruparse hacia la derecha de la curva; o sea, por sobre la media. El valor de la curtosis presentado por el estadístico descriptivo es positivo, por lo que la distribución de los valores observados adoptó una forma leptokurtósica: es decir, la distribución o el polígono es más picudo o elevado. El valor de la prueba de Jarque-Bera rechaza la hipótesis de que las variaciones de los valores semanales de la acción TSLA siga una distribución normal, con un grado de significancia del 5 por ciento. Los estadísticos descriptivos junto a sus coeficientes se presentan en la tabla 1.
Tabla 1. Estadísticos descriptivos para la serie de valores de cierres semanales, en primera diferencia de la acción TSLA
Al desarrollar la estructura para el modelo multivariado dinámico optimizado con fuerza bruta, se utilizó la capacidad de un computador para realizar la evaluación de cada valor estudiado.
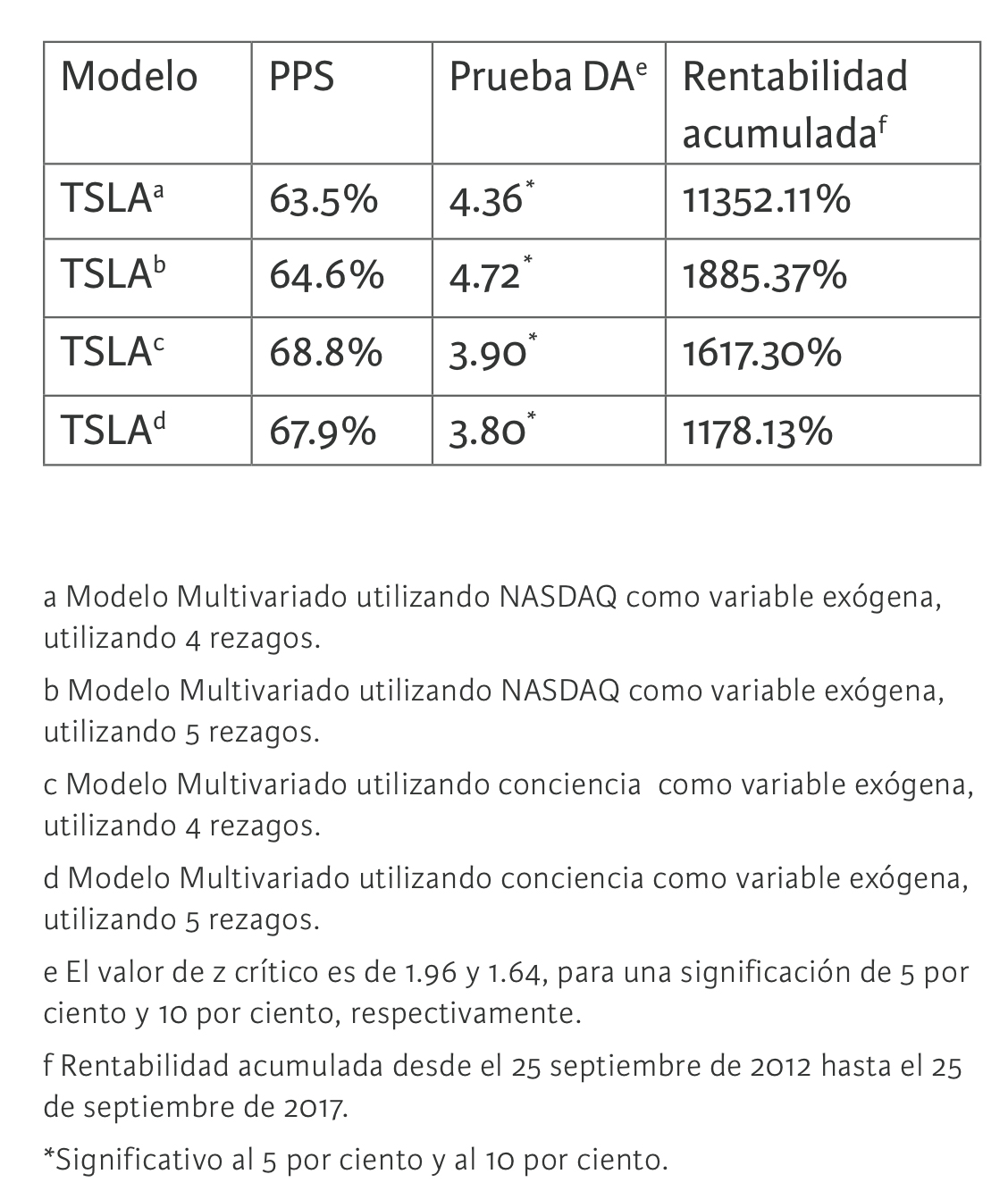
A continuación se presenta el mejor modelo multivariado dinámico para cada caso de estudio de acuerdo con el PPS:
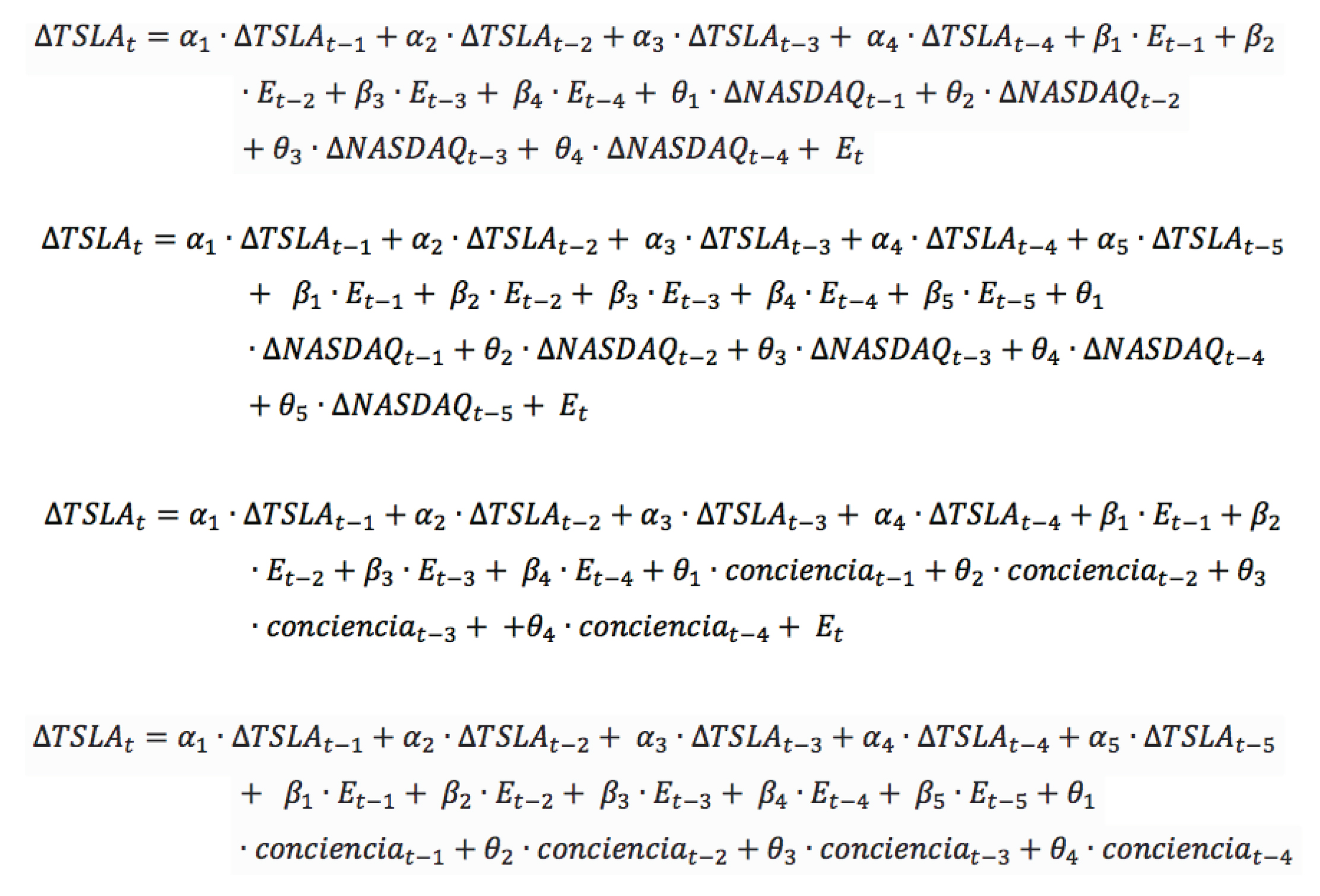
En la tabla 2, según los mejores modelos multivariados dinámicos optimizados con fuerza bruta computacional, se observa respectivamente el porcentaje de predicción de signo para cada modelo en estudio. Para TSLA 7 un PPS de 63.5 por ciento, para TSL 8 un PPS de 64.6 por ciento, para TSLA 9 un PPS 68.8 por ciento y para TSLA 10 un PPS 67.9 por ciento.
Esta capacidad predictiva, estimada en un conjunto extramuestral de 260 datos semanales para los modelos con variable exógena NASDAQ y 109 datos semanales para los modelos con variable exógena conciencia, resultó estadísticamente significativa en cada uno de los valores con un grado de significancia de 5 por ciento y 10 por ciento, de acuerdo con la prueba de acierto direccional, comprobándose así la hipótesis de que sí existe capacidad predictiva en los modelos multivariados optimizados con fuerza bruta para el caso TSLA. Además se pudo observar la rentabilidad acumulada para cada modelo que la capacidad predictiva de estos, traduce en beneficios económicos por medio de la estrategia compra-venta.
Los modelos multivariados dinámicos optimizados con fuerza bruta obtuvieron el PPS esperado entre un 60 por ciento y 70 por ciento según Fama y French (1992). Además, el modelo que arrojó una mayor capacidad predictiva fue cuya variable exógena era el factor conciencia con cuatro rezagos por variable independiente, seguido por otro modelo con variable exógena conciencia pero con cinco rezagos por variable independiente. Estos resultados nos permiten demostrar que para la acción TSLA, la variable que produce en el modelo una mayor capacidad predictiva es el factor conciencia por sobre la variable NASDAQ, la cual fue elegida bajo la primicia de indicador líder (actual) en los mercados bursátiles internacionales propuesta por Parisi, Parisi y Cornejo (2004). Por lo tanto, esta investigación demuestra la eficacia de la utilización de inteligencia artificial en las finanzas.
Tabla 2. Resumen de los resultados
En la tabla 1, 2, 3 y 4 se muestran los mejores coeficientes α, β y θ obtenidos por cada modelo en estudio que maximizan el PPS de la acción TSLA.
Tabla 3. Resumen de los parámetros estimados para la acción TSLA cuatro rezagos

Tabla 4. Resumen de los parámetros estimados para la acción TSLA cinco rezagos

Tabla 5. Resumen de los parámetros estimados para la acción TSLA cuatro rezagos

Tabla 6. Resumen de los parámetros estimados para la acción TSLA cinco rezagos

Se probó la solidez de estos resultados con el fin de evitar el problema de data snooping. Para ello se tomó el mejor modelo de proyección para cada valor y se lo evaluó en un total de cien conjuntos extramuestrales de 260 datos de cierre semanales cada uno para los modelos que incluían como variable exógena el NASDAQ y 109 datos de cierre semanales cada uno para los modelos que incluían como variable exógena el factor conciencia. Estos cien conjuntos extramuestrales fueron generados a partir del conjunto extramuestral original utilizando un proceso de block bootstrap. Al analizar la rentabilidad acumulada que se habría obtenido siguiendo las recomendaciones de compra-venta del modelo multivariado dinámico, se encontró que de los cien conjuntos extramuestrales, estos superaron el rendimiento de una estrategia buy and hold en 182.70 por ciento, 115.96 por ciento, 444.89 por ciento y 8.72 por ciento para los modelos TSLA 11, TSLA 12, TSLA 13 y TSLA 14 respectivamente.
CONCLUSIONES
Este estudio permitió determinar la factibilidad en la construcción de un modelo multivariado dinámico optimizado, con fuerza bruta, con una capacidad de predicción superior a 60 por ciento e inferior a 70 por ciento, según la literatura (Fama y French, 1992), para la acción TSLA.
Los modelos multivariados dinámicos optimizados con fuerza bruta, elaborados a partir de las variables exógenas NASDAQ y conciencia con o sin un rezago adicional, obtuvieron una importante capacidad predictiva. Además, los resultados de la prueba de acierto direccional de Pesaran y Timmermann (1992), indicaron que cada uno de los modelos presentó una capacidad predictiva estadísticamente significativa, con un nivel de significancia de un 5 por ciento y 10 por ciento. A su vez, el modelo que obtuvo la mejor capacidad predictiva en el periodo extramuestral con un 68.81 por ciento de PPS fue cuya variable exógena es el factor conciencia con 4 rezagos por variable independiente. Por lo tanto, se comprueba lo planteado en esta investigación, siendo la variable exógena conciencia la que entrega la mejor capacidad predictiva para la acción TSLA.
El análisis de la rentabilidad acumulada que se obtuvo siguiendo las recomendaciones de compra-venta para el modelo multivariado dinámico optimizado con fuerza bruta que obtuvo la mejor capacidad predictiva, se calculó que de los cien conjuntos extramuestrales, el rendimiento de una estrategia buy and hold fue superado en 444.89 por ciento.
Por lo tanto, esta investigación presenta evidencia empírica de que los modelos multivariados dinámicos en base optimizados con fuerza bruta, pueden ser utilizados como una metodología viable para mejorar los modelos de proyección de series de tiempo en función de su capacidad de predicción de signo. Junto a esto, esta investigación presenta evidencia empírica de la utilización de inteligencia artificial en las finanzas para el desarrollo óptimo de situaciones futuras e inciertas permitiendo una continuación y actualización de las investigaciones propuestas por Parisi, Parisi y Cornejo (2004).
El objetivo de esta investigación es alcanzado íntegramente, de tal forma que se puede utilizar como una herramienta provechosa para todos aquellos actores del mundo financiero cuyo interés está en la solución de este fenómeno de predicción del comportamiento de las acciones, que ha dado vida a este estudio.
REFERENCIAS
Alcaraz, V., Díaz, J., Pérez, R., Frixione, E., Flores, J. y Braunstein, N. (2007). Conciencia, nuevas perspectivas en torno a un viejo problema. México: Siglo Veintiuno editores.
Allen, F. y Karjalainen, R. (1999). Using Genetic Algorithms to Find Technical Trading Rules. Journal of Financial Economics. Pp. 245-271.
Arango, A., Velásquez, J. y Franco, C. (2013). Técnicas de lógica difusa en la predicción de índices de mercados de valores: una revisión de literatura. Revista Ingenierías Universidad de Medellín. Pp. 117-126. Medellín, Colombia.
Atsalakis, G. (2016). Using computational intelligence to forecast carbon prices. Applied Soft Computing Journal. Nº 43. Pp. 107-116.
Baer, R. (1994). Genetic Algorithms and Investment Strategies. Nueva York, EE.UU.: John Wiley & Sons.
Benítez, R., Escudero, G., Kanaan, S. y Rodó, D. M. (2013). Inteligencia Artificial Avanzada. Barcelona: UOC.
Davis, L. (1994). Genetic Algorithms and Financial Applications. En G. Deboeck. Trading on the edge: neural, genetic, and fuzzy systems for chaotic financial markets. Pp. 133-147. Nueva York, EE.UU.: Wiley.
Estrella, A. y Mishkin, F. (1998). Predicting US recessions: Financial variables as leading indicators. The Review of Economics and Statistics. Vol. 80 (Nº1). Pp. 45-61.
Fama, E. y French, K. (1992). The Cross-Section of Expected Stock Returns. Journal of Finance. Pp. 427-465.
Fama, E. (1970). Efficient Capital Markets: a Review of Theoretical and Empirical Work (Vol. 25). Journal of Finance.
Feldman, K. y P. Treleaven (1994). Intelligent Systems in Finance. Appl. Mathematical Finance Nº1. Pp. 195-207.
Hernández, R., Fernández, C. y Baptista, M. (2010). Metodología de la investigación. México: McGraw W-Hill.
Holland, J. (1975). Adaptation in natural and artificial systems: An introductory analysis with applications to biology, control, and artificial intelligence. Ann Arbor, Michigan: University of Michigan Press.
Jaque, M. A. (2014). Modelos de redes neuronales en la predicción del signo de los fondos de AFP Cuprum. Santiago: Universidad de Chile.
Kamenetzky, M. (1999). Conciencia, la Jugadora Invisible. Buenos Aires: Kier.
Kim, K. y Han, I. (2000). Genetic algorithms approach to feature discretization in artificial neural networks for the prediction of stock price index. Expert Systems with Applications. Vol. 19 (Nº2). Pp. 125-132.
Kingdon, J. y Feldman, K. (1995). Genetic algorithms and applications to finance. Applied Mathematical Finance. Vol. 2 (Nº2). Pp. 89-116.
Medina, E. O. (2015). Teorías de la conciencia de orden superior: Rasgos y Problemas. Cuadernos de Filosofia. Nº 54.
Motor, D. (2017). Diario Motor. Recuperado el 1 de Octubre de 2017, de https://www.diariomotor.com/marcas/tesla/
Munárriz, L. Á. (1994). Fundamentos de Inteligencia Artificial. Murcia: Universidad de Murcia.
nasdaq.com. (8 de Agosto de 2017). NASDAQ. Obtenido de http://www.nasdaq.com/symbol/ndaq
Parisi, A., Amestica, L. y Chileno, G. (2016). Modelo predictivo para variaciones de precio del petróleo. Optimización de ARIMA utilizando fuerza bruta operacional. Tesis de grado en ingeniería comercial. Universidad Adeventista de Chile. Chillán, Chile.
Parisi, A., Parisi, F. y Cornejo, E. (2004). Algoritmos genéticos y modelos multivariados recursivos en la predicción de índices bursátiles de América del Norte: IPC, TSE, NASDAQ y DJI. México D. F., México: Red ALyC.
Parisi, A., Parisi, F. y Díaz, D. (2006). Modelos de algoritmos genéticos y redes neuronales en la predicción de índices bursátiles asiáticos. Cuadernos de economía. Santiago: Universidad de Chile.
Parisi, A., Parisi, F. y Guerrero, J. (2003). Modelos predictivos de redes neuronales en índices bursátiles. El Trimestre Económico. Vol. 70 (Nº 4). Pp. 721-744.
Parkin, M. (2004). Economía. México: This One.
Perasso, V. (12 de Octubre de 2016). BBC/Mundo. Obtenido de BBC: http://www.bbc.com/mundo/noticias-37631834
Pereira, R. (1996). Selecting parameters for technical trading rules using genetic algorithms. Journal of Applied Finance and Investment. Vol. 1 (Nº 3). Pp. 27-34.
Pesaran, M. y Timmermann, A. (1992). A simple nonparametric test of predictive performance. Journal of Business and Economic Statistics. Nº 10. Pp. 461-165.
Pierdzioch, C. (2015). Forecasting gold-price fluctuations: a real-time boosting approach. Applied Economics Letters. Vol. 22 (Nº 1). Pp. 46-50.
Qi, M. (2001). Predicting US recessions with leading indicators via neural networks models. International Journal of Forecasting. Nº 17. Pp. 383-401.
Shafiee, S. y Topal, E. (2010). An overview of global gold market and gold price forecasting. Resources Policy. Vol. 35 (Nº 3). Pp. 178-189.
Yahoo/Finanzas. (9 de Agosto de 2017). Yahoo! Finanzas. Obtenido de https://es-us.finanzas.yahoo.com/quote/%5EDJI?p=^DJI
Yahoo/Finanzas. (9 de Agosto de 2017). Yahoo! Finanzas. Obtenido de https://es-us.finanzas.yahoo.com/chart/%5EDJI#eyJtdWx0aUNvbG9yTGluZSI6ZmFsc2UsImJvbGxpbmdlclVwcGVyQ29sb3IiOiIjZTIwMDgxIiwiYm9sbGluZ2VyTG93ZXJDb2xvciI6IiM5NTUyZmYiLCJtZmlMaW5lQ29sb3IiOiIjNDVlM2ZmIiwibWFjZERpdmVyZ2VuY2VDb2xvciI6IiNmZjdiMTIiLCJtYWNkTWFjZENvb
- Incorporar un rezago adicional como variable explicativa significa que el número de combinaciones o de posibles modelos aumentaría desde 4096 a 32768 (215) (Parisi, Parisi y Cornejo, 2004)
- Al momento de aplicar un modelo de algoritmos genéticos se debe identificar correctamente el problema de maximización o minimización por analizar. Si el problema de que se trata no es de ese tipo, se deberá buscar otro método para abordarlo.
- Es el estudio de la cognición de manera integrada a través de disciplinas teóricas y empíricas, como: Filosofía, Sicología, Lingüística, Antropología, Neurociencias y Ciencias de la Computación.
- Random Acces Memory.
- Read-only memory.
- El término data snooping (también conocido como data mining) se utiliza para referirse a un conjunto de datos que han sido usados más de una vez para determinar, inferir o seleccionar modelos. Cuando esto ocurre, siempre existe la posibilidad de que los resultados satisfactorios puedan deberse al factor suerte más que a algún mérito inherente al modelo que generó estos resultados (White, 2000).
Una manera de probar la bondad de los modelos y la validez de sus resultados, independientemente de la muestra de datos a los que han sido aplicados, es utilizar un proceso de bootstrap. El bootstrap es un proceso de generación de observaciones ficticias a partir de datos históricos, con el fin de resolver el problema de escasez de datos y, de este modo, obtener suficiente información para elaborar diferentes conjuntos extramuestrales en los cuales probar la validez de los modelos.
- Modelo Multivariado utilizando NASDAQ como variable exógena, utilizando 4 rezagos.
- Modelo Multivariado utilizando NASDAQ como variable exógena, utilizando 5 rezagos.
- Modelo Multivariado utilizando conciencia como variable exógena, utilizando 4 rezagos.
- Modelo Multivariado utilizando conciencia como variable exógena, utilizando 5 rezagos.
- Modelo Multivariado utilizando NASDAQ como variable exógena, utilizando 4 rezagos.
- Modelo Multivariado utilizando NASDAQ como variable exógena, utilizando 5 rezagos.
- Modelo Multivariado utilizando conciencia como variable exógena, utilizando 4 rezagos.
- Modelo Multivariado utilizando conciencia como variable exógena, utilizando 5 rezagos.