Resumen
Esta investigación extiende la estimación de medidas de bienestar, sugeridas por Hanemann (1984), a medidas de bienestar basadas en la distribución de la disposición a pagar (DAP), para proporcionar información precisa a los decisores de política en relación a la provisión de bienes públicos. Para obtener la distribución de la DAP se usa un método bayesiano propuesto por Benoit y Van den Poel (2012). Finalmente, se realiza una simulación de Monte Carlos para probar el uso de ésta metodología.
1. Introducción
Esta investigación extiende la estimación de medidas de bienestar comúnmente utilizadas en valoración contingente (vc), introduciendo el uso de cuantiles de la disposición a pagar (DAP). Las medidas empleadas tradicionalmente son la media y la mediana, propuestas por Hanemann (1984). La estimación de la distribución de la DAP que se realiza en este estudio se basa en el método bayesiano propuesto por Benoit y Van den Poel (2012). Consideramos que este enfoque de estimación permite generar una información precisa para los decisores de política en relación con la provisión de bienes públicos.
El método de valoración contingente propuesto por Ciriacy y Wantrup (1947) surge ante la ausencia de mercado para los bienes públicos y la imposibilidad de conocer sus precios. Este método permite obtener el valor económico que los individuos le asignan a un bien a partir de la disposición a pagar que tienen por dicho bien. El procedimiento consiste en la aplicación de un cuestionario en el cual se simula un mercado hipotético para el bien en cuestión. El formato referéndum, propuesto por Bishop y Heberlein (1979), en que la respuesta de los individuos relacionada al pago del bien ambiental tiene un forma binaria (sí o no), es uno de los métodos que se usa con mayor frecuencia debido a que es incentivo compatible, es decir induce a revelar honestamente las preferencias de los entrevistados (Arrow et al., 1993).
Con base en los trabajos de Bishop y Heberlein (1979), Hanemann (1984) discute cómo obtener compensaciones hicksianas en modelos con variable dependiente discreta, utilizando un proceso de maximización de utilidad aleatoria. Los resultados que obtiene este autor se basan en las medidas de tendencia central, media y mediana. Johansson et al. (1989) comentan el trabajo de Hanemann (1984), exponiendo la posibilidad de obtener disposiciones a pagar negativas. A partir de esta discusión nace otra medida de bienestar, la media truncada. Esta nueva medida calcula la esperanza de la disposición a pagar considerando solo valores positivos en su integración, descartando los valores negativos.
En la práctica, la valoración que los individuos hacen de un bien ambiental difiere de un individuo a otro, y ello se ve reflejado en la heterogeneidad de la disposición a pagar. Por lo tanto, al usar la media como medida de bienestar, los beneficios de un proyecto que busca proveer un bien público no reflejarán la verdadera valoración del bien y tampoco será posible capturar dicha heterogeneidad, como en el ejemplo anteriormente expuesto. En este sentido, se justifica el uso de la mediana como medida de bienestar ya que, según Hanemann (1984, 1989), desde el punto de vista estadístico, la mediana es más robusta con respecto a los errores y datos atípicos de las respuestas de los encuestados y, a su vez, menos sensible al coeficiente de asimetría y curtosis de los datos (Staving y Gibbons, 1977). En este sentido, el criterio de Kaldor-Hicks, que usa la media para la agregación de resultados, no es adecuado desde el punto de vista teórico, cuando la disposición a pagar es heterogénea.
Adicionalmente, Hanemann (1989) plantea la necesidad de utilizar no solo el cuantil 0.5 (mediana) como medida de bienestar, sino también otros cuantiles de interés que puedan capturar información para una parte específica de la población. La estimación de la distribución de la disposición a pagar puede contribuir a responder necesidades de información específica. Por ejemplo, se puede estar interesado en conocer cuánto está dispuesto a pagar el 25% de la población por un proyecto que mejora la calidad del aire.
Para estimar los cuantiles de la disposición a pagar, utilizamos un método bayesiano de regresión binaria sugerido por Benoit y Van den Poel (2012). Este método presenta tres ventajas respecto del tradicional sugerido por Manski (1975, 1985), Horowitz (1992) y Kordas (2006). Primero, facilidad en la estimación e inferencia; segundo, convergencia de parámetros en muestras pequeñas; por último, las estimaciones funcionan correctamente cuando existen problemas de heterocedasticidad en la varianza del error.
2. Modelo teórico
2.1 Modelo de diferencia de la función indirecta de utilidad
En valoración contingente, los formatos de encuesta tipo referendum propuestos por Bishop y Heberlein (1987) tienen dos enfoques para modelar la elección discreta de los consumidores: el modelo de Hanemann (1984), denominado modelo de diferencia de la función indirecta de utilidad, y el de Cameron (1988), conocido como modelo de la función de variación. La diferencia entre ambos enfoques se centra en la forma de definir la variable latente y la interpretación de los parámetros. Esta investigación pretende extender el uso de las medidas sugeridas por Hanemann, por lo tanto empleamos el enfoque de diferencia de la función indirecta de utilidad. Sin embargo, en principio podemos ocupar ambos métodos, teniendo presente que la interpretación de los parámetros será diferente1.
Lo que intentamos modelar es la respuesta de los individuos ante la pregunta: ¿estaría dispuesto usted a pagar una cantidad igual a $A para realizar un proyecto de mejora en la calidad ambiental del recurso?, siendo las posibles repuestas “sí” o “no”. Entonces, sea ![]() , la función indirecta de utilidad de un individuo en particular, donde
, la función indirecta de utilidad de un individuo en particular, donde ![]() representa la mejora en la calidad del recurso y
representa la mejora en la calidad del recurso y ![]() la situación contraria,
la situación contraria, ![]() es un vector de precios que enfrenta el individuo por sus bienes,
es un vector de precios que enfrenta el individuo por sus bienes, ![]() es el ingreso familiar y
es el ingreso familiar y ![]() es un vector de calidad de los bienes que puede incorporar características socioeconómicas de los individuos. El investigador no puede observar la verdadera función indirecta de utilidad del individuo, solo una parte de ella, por lo tanto podemos asumir que cada función tiene un componente determinístico y otro estocástico, es decir:
es un vector de calidad de los bienes que puede incorporar características socioeconómicas de los individuos. El investigador no puede observar la verdadera función indirecta de utilidad del individuo, solo una parte de ella, por lo tanto podemos asumir que cada función tiene un componente determinístico y otro estocástico, es decir:
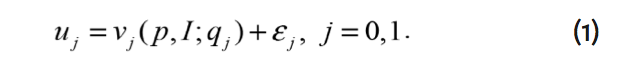
Donde ![]() es el componente estocástico no observado por el investigador. Siguiendo a McConnell y Kenneth (1990), un modelo de valoración contingente enfrenta al individuo a una elección en cuanto a una mejora en la calidad ambiental (de
es el componente estocástico no observado por el investigador. Siguiendo a McConnell y Kenneth (1990), un modelo de valoración contingente enfrenta al individuo a una elección en cuanto a una mejora en la calidad ambiental (de ![]() a
a ![]() ), por lo cual se debe pagar una cantidad
), por lo cual se debe pagar una cantidad ![]() o no tener la mejora y no pagar. Sin embargo, la verdadera valoración del recurso (denotada por
o no tener la mejora y no pagar. Sin embargo, la verdadera valoración del recurso (denotada por ![]() ) no es observable y lo único que es factible saber a partir de la respuesta de los individuos es si esta es mayor o menor que la cantidad ofrecida
) no es observable y lo único que es factible saber a partir de la respuesta de los individuos es si esta es mayor o menor que la cantidad ofrecida ![]() . Por lo tanto, el individuo aceptará pagar dicha cantidad siempre y cuando la utilidad de la mejora sea mayor que la utilidad sin la mejora,
. Por lo tanto, el individuo aceptará pagar dicha cantidad siempre y cuando la utilidad de la mejora sea mayor que la utilidad sin la mejora, ![]() . Lo anterior se puede escribir en términos de probabilidad de la siguiente forma:
. Lo anterior se puede escribir en términos de probabilidad de la siguiente forma:
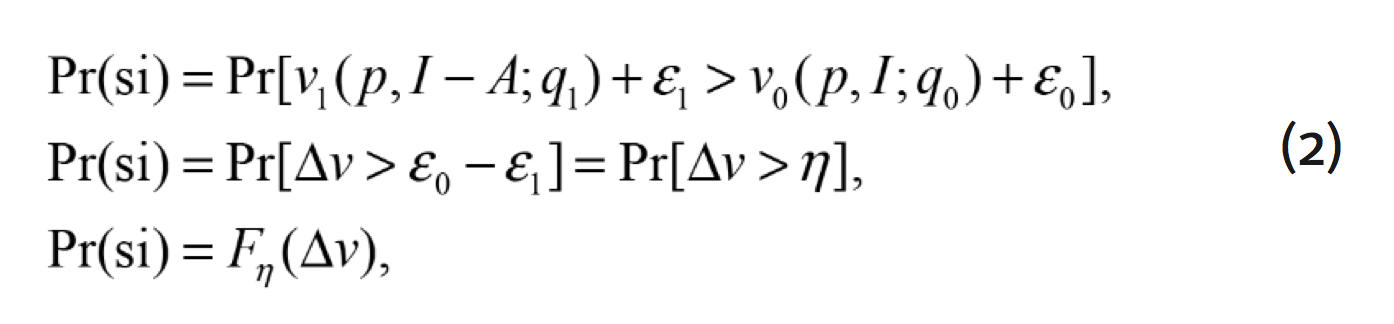
donde ![]() es la función de distribución acumulada de
es la función de distribución acumulada de ![]() . Si se asume que
. Si se asume que ![]() es normal, entonces se estima un modelo probit; por el contrario, si se asume que
es normal, entonces se estima un modelo probit; por el contrario, si se asume que ![]() se distribuye logísticamente, se estima el modelo logit (Kotz et al., 2001), el cual muestra que se puede construir una variable con distribución asimétrica de Laplace a partir de dos variables exponenciales estándar. Por lo tanto, esta investigación asume que
se distribuye logísticamente, se estima el modelo logit (Kotz et al., 2001), el cual muestra que se puede construir una variable con distribución asimétrica de Laplace a partir de dos variables exponenciales estándar. Por lo tanto, esta investigación asume que ![]() y
y ![]() son i.i.d. con distribución exponencial estándar, luego
son i.i.d. con distribución exponencial estándar, luego ![]() sigue una distribución asimétrica de Laplace (ALD) de la forma
sigue una distribución asimétrica de Laplace (ALD) de la forma
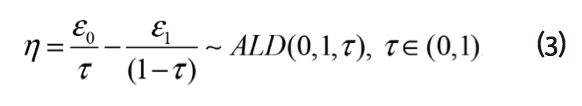
La media y desviación estándar son iguales a 0 y 1, respectivamente. ![]() es el parámetro de asimetría.
es el parámetro de asimetría.
Siguiendo a Hanemann (1984), se utiliza una función indirecta de utilidad lineal ![]() , donde
, donde![]() , por lo tanto
, por lo tanto
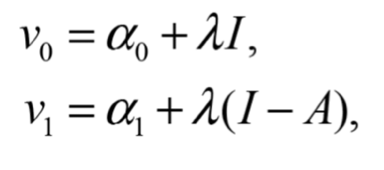
indican la situación sin la mejora en la calidad ambiental y la situación con la mejora, respectivamente. En este caso se asume que las dos alternativas, aceptar o rechazar la mejora en la calidad ambiental, son sustitutos perfectos. Para encontrar ![]() , perteneciente a la ecuación (1.2), diferenciamos
, perteneciente a la ecuación (1.2), diferenciamos ![]() y
y ![]() ,
,
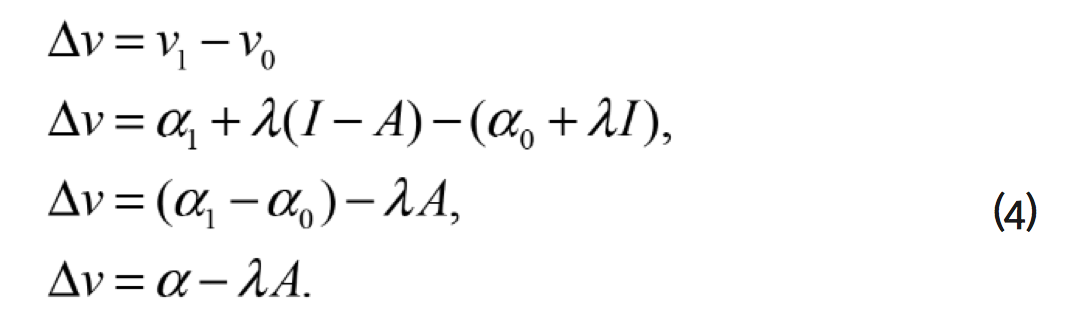
2.2 Medidas de bienestar clásicas
Las medidas de bienestar hicksianas, como la variación compensada, representan la cantidad de dinero que un individuo está dispuesto a pagar por acceder a una mejora en la calidad ambiental, y la denotamos por ![]() . La cantidad de dinero
. La cantidad de dinero ![]() es usada como compensación para que el individuo mantenga su nivel de utilidad constante después de aceptar la mejora en la calidad ambiental, es decir se cumple
es usada como compensación para que el individuo mantenga su nivel de utilidad constante después de aceptar la mejora en la calidad ambiental, es decir se cumple
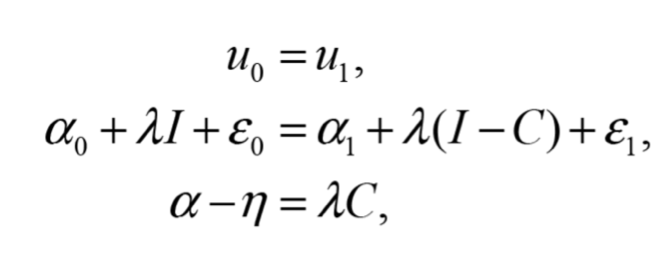
despejando con respecto a ![]()

Donde ![]() y
y ![]() son los parámetros del modelo logit o probit. Sin embargo, la ecuación (6) es una estimación simplificada de la disposición a pagar, puesto que entrega solo un valor (promedio) de la DAP. No muestra su heterogeneidad y su inferencia resulta complicada, ya que se debe utilizar el método Delta para calcular su varianza. Además,
son los parámetros del modelo logit o probit. Sin embargo, la ecuación (6) es una estimación simplificada de la disposición a pagar, puesto que entrega solo un valor (promedio) de la DAP. No muestra su heterogeneidad y su inferencia resulta complicada, ya que se debe utilizar el método Delta para calcular su varianza. Además, ![]() no tiene distribución teórica conocida, por lo tanto su inferencia es cuestionable. Para generar intervalos se usan técnicas de remuestreo, como boostrap, pero estas siguen siendo válidas para la media de
no tiene distribución teórica conocida, por lo tanto su inferencia es cuestionable. Para generar intervalos se usan técnicas de remuestreo, como boostrap, pero estas siguen siendo válidas para la media de ![]() . En este estudio extendemos el uso de la media y mediana a otros cuantiles de las medidas de bienestar. Para ello se utiliza la especificación expuesta en el siguiente punto.
. En este estudio extendemos el uso de la media y mediana a otros cuantiles de las medidas de bienestar. Para ello se utiliza la especificación expuesta en el siguiente punto.
3. Distribución de la disposición a pagar (DAP)
Para obtener la distribución de la DAP, asumiendo un enfoque de regresión por cuantiles ![]() , se retoma la idea anterior, donde
, se retoma la idea anterior, donde ![]() representa la ecuación asociada a la estimación por cuantiles. Al descomponer esta ecuación, podemos obtener de la siguiente forma:
representa la ecuación asociada a la estimación por cuantiles. Al descomponer esta ecuación, podemos obtener de la siguiente forma:
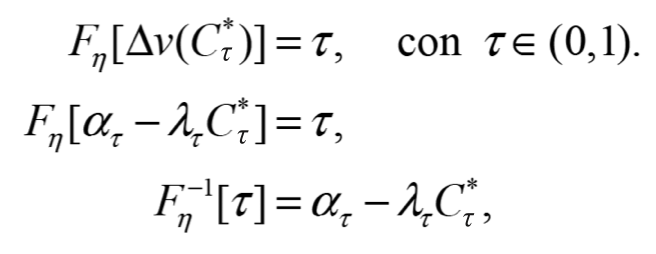
despejamos con respecto a ![]() para obtener los cuantiles de la medida de bienestar,
para obtener los cuantiles de la medida de bienestar,
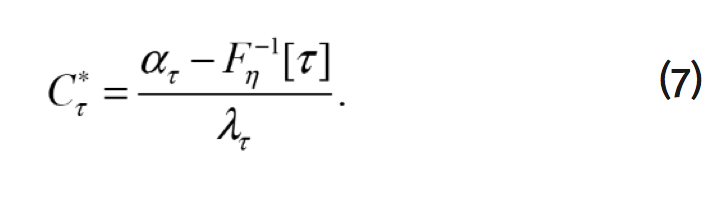
Donde ![]() es la función de distribución asimétrica de Laplace acumulada, con parámetro de localización 0 y parámetro de escala igual a 1.
es la función de distribución asimétrica de Laplace acumulada, con parámetro de localización 0 y parámetro de escala igual a 1. ![]() y
y ![]() son los parámetros que provienen de la estimación binaria por cuantiles.
son los parámetros que provienen de la estimación binaria por cuantiles. ![]() es la probabilidad
es la probabilidad ![]() de que un individuo esté dispuesto a pagar una cantidad
de que un individuo esté dispuesto a pagar una cantidad ![]() menor o igual a
menor o igual a ![]() ,
, ![]()
![]() es la probabilidad
es la probabilidad ![]() de que un individuo esté dispuesto a pagar una cantidad menor o igual a
de que un individuo esté dispuesto a pagar una cantidad menor o igual a ![]() . Si
. Si ![]() , entonces
, entonces ![]() es igual a 0, por lo tanto,
es igual a 0, por lo tanto, ![]() , que es similar a la ecuación (6).
, que es similar a la ecuación (6).
4. Especificación del modelo econométrico
Dado que la diferencia de la función indirecta de utilidad para cada individuo es una variable latente no observada, utilizamos un modelo de regresión binario,
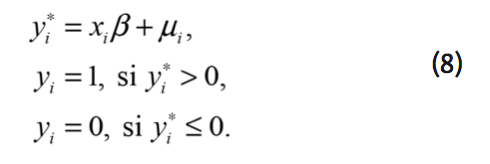
Donde ![]() es un indicador de la i-ésima respuesta del individuo ante la pregunta: ¿estaría dispuesto usted a pagar una cantidad igual a $A, para realizar un proyecto de mejora en la calidad ambiental del recurso?
es un indicador de la i-ésima respuesta del individuo ante la pregunta: ¿estaría dispuesto usted a pagar una cantidad igual a $A, para realizar un proyecto de mejora en la calidad ambiental del recurso? ![]() es la variable latente correspondiente al diferencial de la función de utilidad indirecta
es la variable latente correspondiente al diferencial de la función de utilidad indirecta ![]() ,
, ![]() es un vector de variables explicativas de orden
es un vector de variables explicativas de orden ![]() ,
, ![]() es un vector de parámetros de orden
es un vector de parámetros de orden ![]() y
y ![]() es el error que se distribuye ALD, con parámetro de localización igual a 0, parámetro de escala igual a 1 y parámetro de asimetría igual a
es el error que se distribuye ALD, con parámetro de localización igual a 0, parámetro de escala igual a 1 y parámetro de asimetría igual a ![]() .
.
Sin embargo, si se está interesado en un modelo de regresión binaria por cuantiles, siguiendo a Ji et al. (2012), el estimador del ![]() cuantil de una regresión binaria está dado por
cuantil de una regresión binaria está dado por

donde ![]() es una función indicadora y
es una función indicadora y ![]() es la función de pérdida. Definida por
es la función de pérdida. Definida por
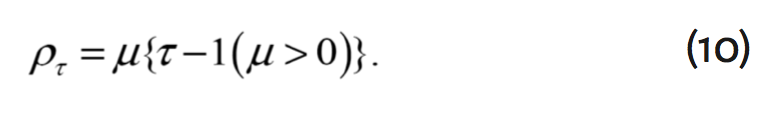
Koenker y Machado (1999) fueron los primeros en mostrar la relación entre la función de pérdida anterior y la función de distribución asimétrica de Laplace (ALD), es decir se puede mostrar que es equivalente a minimizar el problema asociado a la ecuación (11) y maximizar la función de verosimilitud de una variable aleatoria ALD. Esta dualidad se da por la igualdad entre sus funciones de pérdida asimétricas. Algo similar ocurre entre el problema de mínimos cuadrados ordinarios (MCO) y el error aleatorio con distribución normal. En este último caso, ambos poseen una función de pérdida cuadrática, siguiendo a Benoit y Van den Poel (2012), quienes usan un enfoque bayesiano basados en una distribución asimétrica de Laplace (ALD) para estimar la regresión por cuantiles binarias.
5. Simulación de Monte Carlo
Con el fin de ejemplificar el uso de la metodología propuesta para estimar la distribución de la disposición a pagar, se simula la función de utilidad aleatoria para luego derivar la DAP dado un cuantil específico de su distribución. Primero,
![]()
Es la función de utilidad aleatoria, donde ![]() y . A partir de la ecuación (6) se obtiene la media de la DAP que es igual a . Asumiendo que si , y si se reescribe la ecuación anterior como:
y . A partir de la ecuación (6) se obtiene la media de la DAP que es igual a . Asumiendo que si , y si se reescribe la ecuación anterior como:
![]()
Luego, se estima el método de regresión por cuantiles binarias. Con un tamaño de muestra de 2000 se realizan 1000 repeticiones del experimento de Monte Carlo. El resultado de los parámetros y la DAP se muestran en la siguiente tabla:
Tabla 1. Cinco cuantiles de la distribución de la disposición a pagar
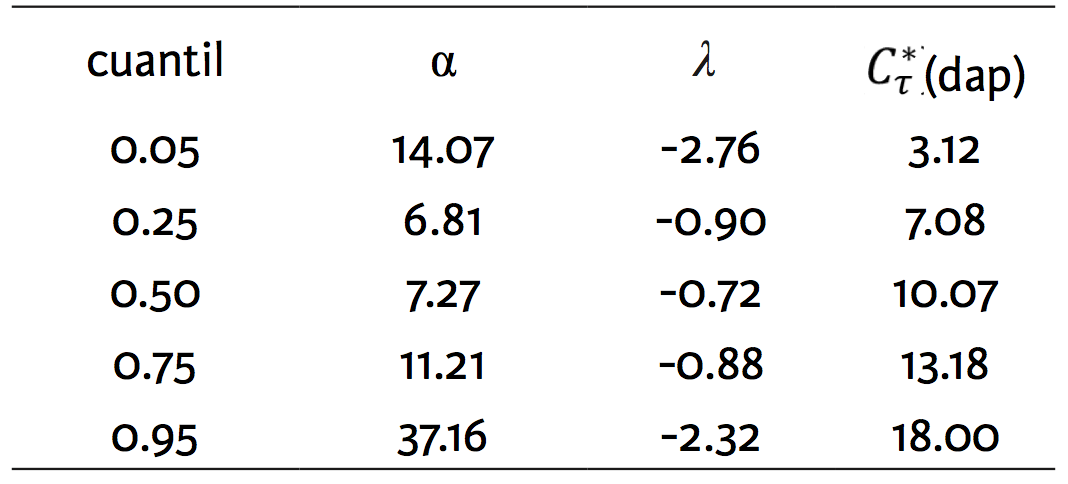
La interpretación de la disposición a pagar para un cuantil específico, en el caso de ![]() según la ecuación (7), es la siguiente: dado el cuantil 0.05 se observa una disposición a pagar (DAP) igual a 3.12, es decir el 5% de la población está dispuesto a pagar una cantidad menor o igual a 3.12. Por otro lado, el 50 % de la población estaría dispuesto a pagar 10.07, que es similar a la cantidad teórica previamente estimada
según la ecuación (7), es la siguiente: dado el cuantil 0.05 se observa una disposición a pagar (DAP) igual a 3.12, es decir el 5% de la población está dispuesto a pagar una cantidad menor o igual a 3.12. Por otro lado, el 50 % de la población estaría dispuesto a pagar 10.07, que es similar a la cantidad teórica previamente estimada ![]() .
.
Si solo se consideran las medidas de bienestar media y mediana, no es posible capturar la evidente heterogeneidad de la DAP. Por otro lado, la estimación por cuantiles sugiere que el cálculo de los beneficios individuales y agregados de un proyecto que intente proveer un bien ambiental será sensible a los cuantiles de la DAP.
6. Conclusión
La estimación de la distribución de la disposición a pagar permite observar su heterogeneidad y genera información precisa que podría ser usada por los decisores de política, en relación a la provisión de bienes públicos. Al considerar medidas de bienestar basadas solo en la media y en la mediana, el análisis costo-beneficio puede presentar errores en el cálculo de los beneficios asociados a un proyecto de mejora en la calidad ambiental.
Con respecto a la medida de bienestar más adecuada, se sugiere lo siguiente: si la DAP entre los cuantiles es homogénea, no hay problema con la elección de la medida de bienestar puesto que no habrá cambios significativos en los cuantiles de la DAP. Por el contrario, si la DAP es heterogénea, la elección de una medida de bienestar sobre un cuantil específico afecta el cálculo de los beneficios individuales y agregados de un proyecto. No obstante, como menciona Hanemann (1989), esta decisión implica un tema de carácter ético y, por lo tanto, se podría decir que ninguna medida de bienestar, en principio, es mejor que otra.
Bibliografía
Arrow, K. et al. (1993). Report of the NOAA Panel on Contingent Valuation.
Benoit, D.F. y Van den Poel, D. (2012). Binary quantile regression: a Bayesian approach based on the asymmetric Laplace distribution. Journal of Applied Econometrics (27), pp. 1174-1188.
Bishop, R.C., Heberlein, T.A. (1979). Measuring values of extra-market goods: Are indirect measures biased? American Journal of Agricultural Economics (61), pp. 926-930.
Cameron, T.A. (1989). A New Paradigm for Valuing Non-Market Goods Using Referendum Data: Maximum Likelihood Estimation by Censored Logistic Regression. Journal of environmental economics and management (55), pp. 355-379.
Ciriacy-Wantrup, S.V. (1947). Capital returns from soil-conservation practices. Journal Farm Economics (29), pp. 1181-1196.
Hanemann, W.M. (1984). Welfare Evaluations in Contingent Valuation Experiments with Discrete Responses. American Journal of Agricultural Economics (66), pp. 332-341.
Hanemann, W.M. (1989). Welfare evaluations in contingent valuation experiments with discrete response data: Reply. American Journal of Agricultural Economics (71), pp. 1057-1061.
Horowitz, J.L. (1992). A smoothed maximum score estimator for the binary response model. Econometrica (60), pp. 505-531.
Ji, Y., Lin, N., Zhang, B. (2012). Model selection in binary and tobit quantile regression using the Gibbs sampler. Computational Statistics & Data Analysis (56), pp. 827-839.
Johansson, P.-O., Kristom, B. y Maler, K.G. (1989). Welfare evaluations in contingent valuation experiments with discrete response data: comment. American Journal of Agricultural Economics (71), pp. 1055-1056.
Koenker, R. y Machado, J.A.F. (1999). Goodness of fit and related inference processes for quantile regression. Journal of the American Statistical Association (94), pp. 1296-1310.
Kordas, G., 2006. Smoothed binary regression quantiles. Journal of Applied Econometrics (21), pp. 387-407.
Kotz, S., Kozubowski, T.J. y Podgórski, K. (2001). The Laplace Distribution and Generalizations: A Revisit with Applications to Communications, Economics, Engineering and Finance. Birkhauser: Boston, MA.
McConnell, K.E. (1990). Models for Referendum Data: the Structure of Discrete Choice Models for Contingent Valuation. Journal of Environmental Economics and Management (18), pp. 19-34.
Manski, C.F. (1975). Maximum score estimation of the stochastic utility model of choice. Journal of Econometrics (3), pp. 205-228.
Manski, C.F. (1985). Semiparametric analysis of discrete response: asymptotic properties of the maximum score estimator. Journal of Econometrics (27), pp. 313-333.
Vásquez, L.F., Cerda, U.A., Orrego, S.S. (2007). Valoración Económica del Ambiente. Fundamentos Económicos, Econométricos y Aplicaciones. Thomson Learning. Buenos Aires.